


欢迎关注我,获取我的更多笔记分享
大家好,我是极智视界,本文解读一下 一种用于深度学习的端到端自动优化编译器 TVM。

现在越来越需要将机器学习部署到各种硬件设备,当前的框架依赖于供应商特定的算子,并只是针对范围较窄的服务器级的 GPU 进行了优化。将工作负载部署到新平台:例如手机、嵌入式设备和加速器 (例如 FPGA、ASIC 等),需要大量的手工工作。作者提出了 TVM,这是一种公开了 graph级别 和 算子级别的优化,在跨不同硬件后端的深度学习工作负载的情况下也能表现优秀的性能。TVM 解决了深度学习特有的优化挑战,例如高级算子融合、映射到任意硬件原语 和 内存延迟隐藏。它还通过采用一种新颖的、基于学习的成本建模方法来快速搜索代码优化,从而自动优化低级程序以适应硬件特性。实验结果表明,TVM 提供的跨硬件后端性能可与用于低功耗 CPU、移动 GPU 和 服务器级GPU 的最先进的手动调整库相媲美。另外作者还展示了 TVM 针对新加速器后端的适应能力,例如基于 FPGA 的通用深度学习加速器。值得一提的是,TVM 是开源的,并已经在几家大厂内用于生产。
论文地址:https://www.usenix.org/system/files/osdi18-chen.pdf
github地址:https://github.com/apache/tvm
源码不限速下载地址(v0.11版本&包含三方库):https://download.csdn.net/download/weixin_42405819/86815389?spm=1001.2014.3001.5503
源码不限速下载地址(v0.10版本&包含三方库):https://download.csdn.net/download/weixin_42405819/86815386
深度学习模型 (DL) 现在可以用来识别图像、处理自然语言,并在具有挑战性的策略游戏中击败人类。从云服务器到自动驾驶汽车和嵌入式设备,将智能应用程序部署到各种设备的需求在不断增长。由于硬件特性的多样性,包括嵌入式 CPU、GPU、FPGA 和 ASIC (例如 TPU),将 DL 工作负载映射到这些设备变得复杂。这些硬件目标在内存组织、计算功能单元等方面存在差异,如图1所示。
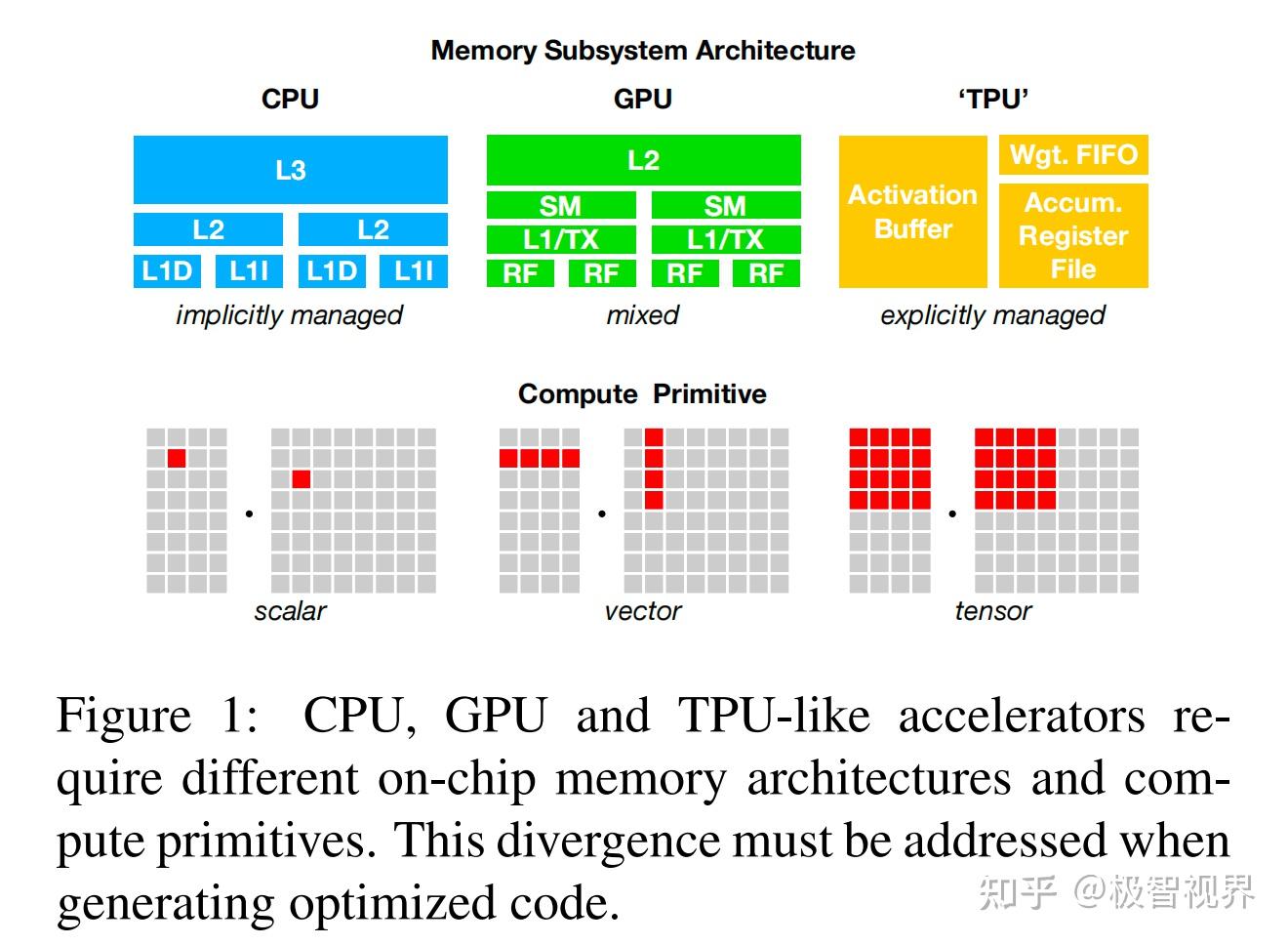
当前的 DL 框架,如 TensorFlow、MXNet、Caffe 和 PyTorch,依靠计算图中间表示来实现优化,例如自动微分 和 动态内存管理。然而,图级优化通常过于高级,无法处理特定于硬件后端的算子级别的转换。这些框架中的大多数都专注于一小类服务器级 GPU 设备,针对特定目标的优化依赖于高度工程化和特定于供应商的算子库。这些算子级别的库需要大量的手动调整,因此过于专业且不透明,无法轻松跨硬件设备移植。目前,在各种 DL 框架中为各种硬件后端提供支持需要大量的工程努力。即使对于已经支持的后端,框架也必须在以下之间做出艰难的选择:(1) 避免产生不在预定义算子库中的新算子的图优化;(2) 使用这些新算子的未优化的视线。为了对不同的硬件后端启用图级 和 算子级的优化,作者采用了一种完全不同的端到端的方法。作者构建了 TVM,这是一个编译器,它从现有框架中获取深度学习程序的高级规范,并为各种硬件后端生成低级优化代码。为了吸引更多用户,TVM 需要提供与跨不同硬件后端的大量手动优化的算子库相比 具有竞争力的性能。这一目标需要解决下面描述的关键挑战。
Levaraging specific Hardware Features and Abstractions DL 加速器引入了优化的张量加速原语,而 GPU 和 CPU 则不断改进其处理元素。这对为给定的算子描述生成优化代码提出了重大挑战。硬件指令的输入是多维的,具有固定或可变长度;他们决定了不同的数据布局;他们对内存层次结构有特殊要求。系统必须有效地利用这些复杂的原语才能从加速中受益。此外,加速器设计通常也支持更加精简的控制,并将大多数调度复杂性下放到编码器堆栈。对于专用加速器,系统需要生成显式控制管道依赖关系的代码,以隐藏内存访问延迟 - 这是硬件为 CPU 和 GPU 执行的一项工作。
Large Search Space for Optimization 另一个挑战是在不手动调整算子的情况下生成高效的代码。内存访问、线程模式和新颖的硬件原语的组合选择为生成的代码 (例如 循环块、排序、缓存 和 展开) 创建了巨大的配置空间,如果要实现黑盒自动调整,将需要大量的搜索成本。可以采用预定义的成本模型来指导搜索,但由于现代硬件的复杂性日益增加,构建准确的成本模型很困难。此外,这种方法需要我们为每种硬件类型建立单独的成本模型。
TVM 通过三个关键模块解决了这些挑战。(1) 引入张量表达式语言来构建算子并提供程序转换原语,这些原语可以生成具有各种优化的不同版本的程序。这个 layer 扩展了 Halide 的计算 / 调度分离概念,还将目标硬件内在函数与转换原语分离,从而支持新的加速器 及其 相应的新内在函数。此外,引入了新的转换原语来解决与 GPU 相关的挑战,并支持部署到专门的加速器。然后应用不同的程序转换序列,为给定的算子声明形成一个丰富的有效程序空间。(2) 引入了一个自动程序优化框架来寻找优化的张量算子。优化器由基于 ML 的成本模型指导,随着我们从硬件后端收集更多的数据,该模型会适应和改进。(3) 在自动代码生成器之上,引入了一个 graph重写器,它充分利用了高级 和 算子级别的优化。
通过结合这三个模块,TVM 可以从现有的深度学习框架中获取模型描述,执行高级和低级联合优化,并为后端生成特定于硬件的优化代码,例如 CPU、GPU 和 基于FPGA的专用加速器。本文的贡献如下:
- 确定了为跨不同硬件后端的深度学习工作负载提供性能可移植性方面的主要优化挑战;
- 介绍了利用跨线程内存重用、新颖的硬件内在函数 和 延迟隐藏的新颖调度原语;
- 提出并实现了一个基于机器学习的优化系统,以自动搜索和搜索优化的张量算子;
- 构建了一个端到端的编译和优化堆栈,允许将高级框架 (TensorFlow、MXNet、PyTorch、Kears、CNTK) 中指定的深度学习工作负载部署到不同的硬件后端 (包括 CPU、服务器 GPU、移动 GPU 和 基于FPGA的加速器);
- 开源 TVM 在几家大公司内用于生产;
使用服务器级GPU、嵌入式GPU、嵌入式CPU 和 基于FPGA 的定制通用加速器上的真实工作负载评估了 TVM。实验结果表明,TVM 提供了跨后端的可移植性能,并且比由手动优化库支持的现有框架实现了 1.2 倍到 3.8 倍的加速。
本节通过一个示例来介绍 TVM 的组件。图2总结了 TVM 中的执行步骤及其在论文中的相应部分。
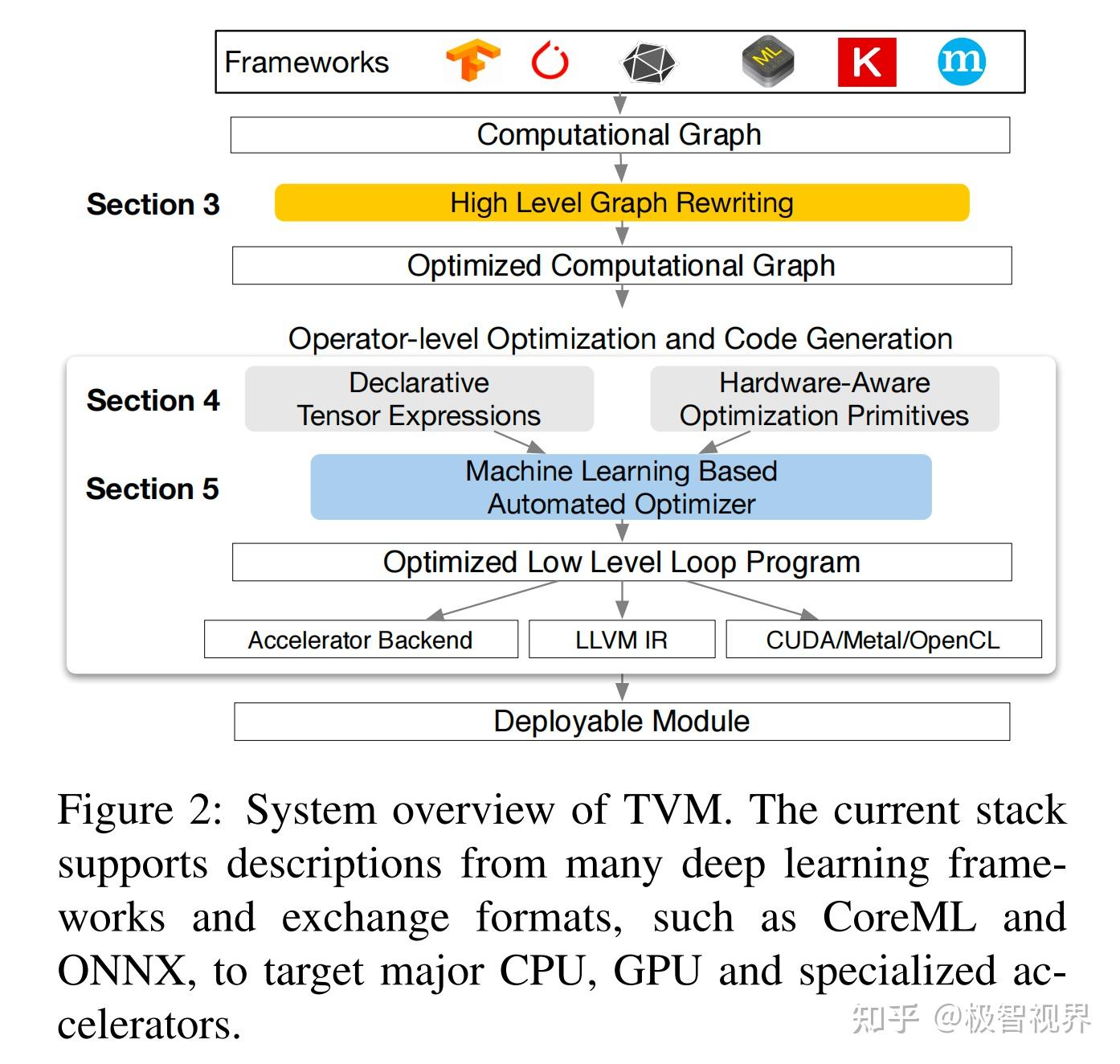
该系统首先将来自现有框架的模型作为输入,并将其转换为计算图表示。然后它执行高级数据流重写以生成优化图。算子级优化模块必须为该图中的每个融合算子生成高效代码。算子以声明性张量表达式语言指定;执行细节未指定。TVM 为给定硬件目标的算子识别一组可能的代码优化。可能的优化形成了很大的空间,因此使用基于 ML 的成本模型来寻找优化的算子。最后,系统将生成的代码打包到一个可部署的模块中。
End-User Example 只需要几行代码,用户就可以从现有的深度学习框架中获取模型并调用 TVM API 以获取可部署的模块:
import tvm as t
# Use keras framework as example, import model
graph, params = t.frontend.from_keras(keras_model)
target = t.target.cuda()
graph, lib, params = t.compiler.build(graph, target, params)这个编译后的运行时模块包含三个组件:最终优化的计算图 (graph)、生成的算子 (lib) 和 模块参数 (params)。然后可以使用这些组件将模型部署到目标后端:
import tvm.runtime as t
?
module = runtime.create(graph, lib, t.cuda(0))
module.set_input(**params)
module.run(data=data_array)
output = tvm.nd.empty(out_shape, ctx=t.cuda(0))
module.get_output(0, output)TVM 支持多种语言的部署后端,例如 C++、Java 和 Python。后面的其余部分描述了 TVM 的架构以及系统程序员如何扩展它以支持新的后端。
计算图是在 DL 框架中表示程序的常用方法。图3展示了一个两层卷积网络的示例计算图表示。
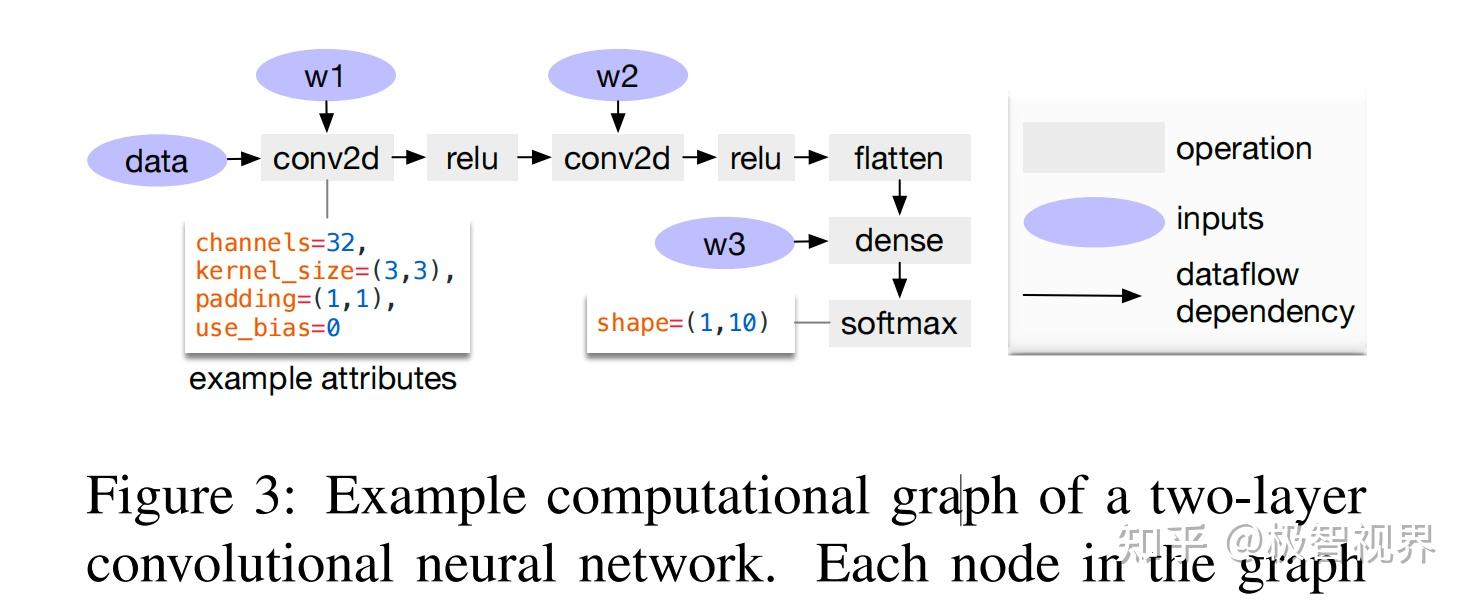
这种高级表示与低级编译器中间表示 (IR) (如 LLVM) 之间的主要区别在于:中间数据项是大型的多维张量。计算图提供了算子的全局视图,但它们避免指定每个算子必须如何实现。与 LLVM IR 一样,计算图可以转换为功能等效的图以应用优化。作者还利用常见 DL 工作负载中的形状特异性来优化一组固定的输入形状。
TVM 利用计算图表示来应用高级优化:节点表示对张量或程序输入的操作,边表示操作之间的数据依赖关系。它实现了许多图级优化,包括:算子融合,将多个小操作融合在一起;常量折叠,预先计算可以静态确定 graph 部分,节省执行成本;一个静态内存规划 pass,它预先分配内存来保存每个中间张量;数据排布转换,将内部数据排布转换为后端友好的形式。接下来讨论算子融合和数据排布转换。
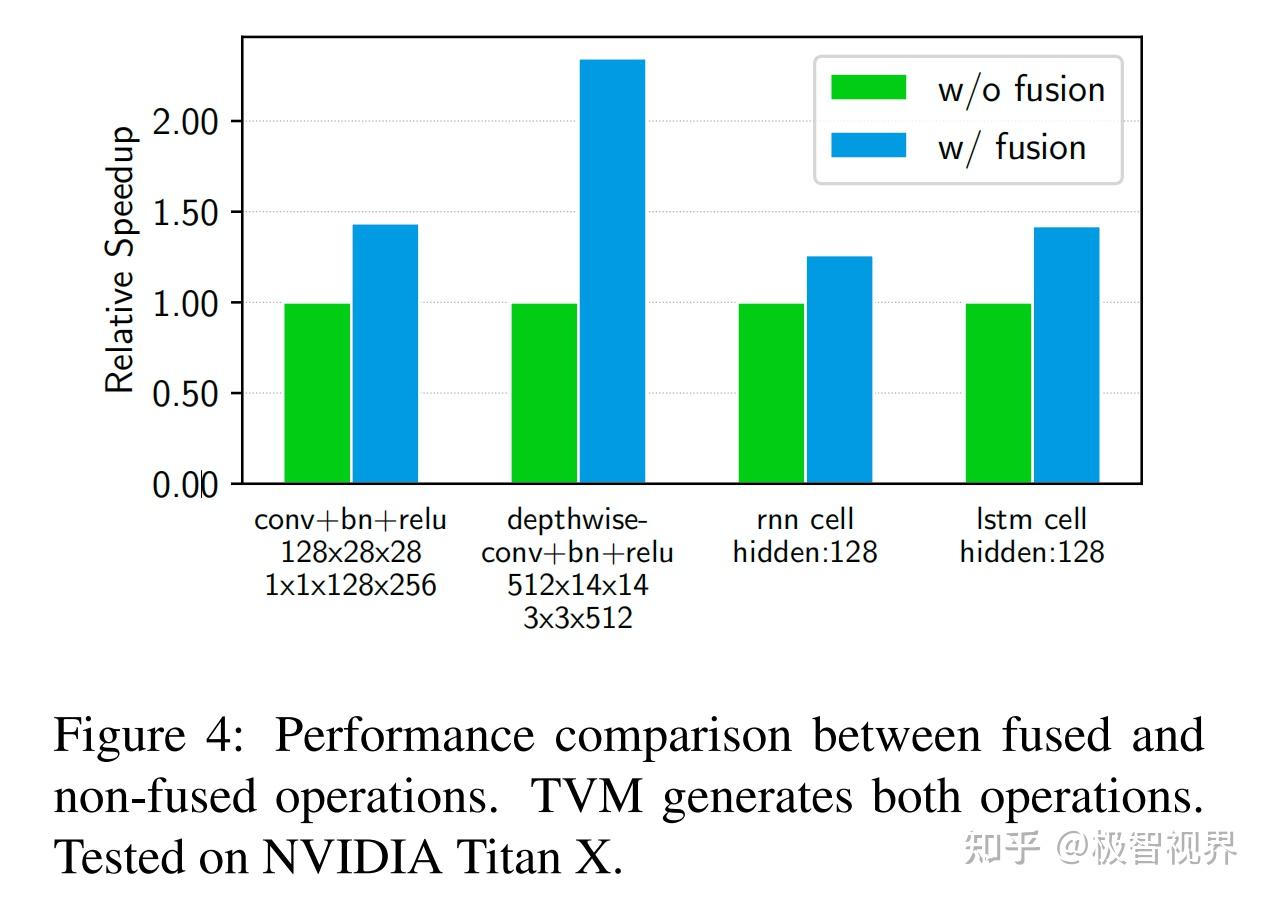
Operator Fusion 算子融合将多个算子组合到一个内核中,而不会将中间结果保存在内存中。这种优化可以大大减少执行时间,尤其是在 GPU 和专用加速器中的执行时间。具体来说,有四类 graph 算子:(1) injective (一对一映射,例如 add);(2) reduction (例如 sum);(3) complex-out-fusable (可以将元素映射融合到输出,例如 conv2d);(4) opaque (不能融合的,例如 sort)。这里提供了融合这些算子的通用规则,如下所示。多个 injective 算子可以融合成另一个 injective 算子。reduction 算子可以与输入 injective 算子融合 (例如 融合 scale 和 sum)。诸如 conv2d 之类的算子是 complex-out-fusable 的,咱们可以将元素算子融合到它的输出中。可以应用这些规则将计算图转换为融合版本。图4展示了这种优化对不同工作负载的影响。作者发现融合算子通过减少内存访问会产生高达 1.2 到 2 倍的加速。
Data Layout Transformation 有多种方法可以在计算图中存储给定的张量。最常见的数据排布选择是 列主序 和 行主序。在实践中,咱们可能会更加喜欢使用更加复杂的数据排布。例如,DL 加速器可能会采用 4X4 矩阵运算,需要将数据排布平铺成 4X4 块以优化访问局部性。
数据排布优化将计算图转换为 可以使用更加好的内部数据排布 以在目标硬件上执行计算图。它首先在给定内存层次结构规定的约束条件下为每个算子指定首选数据排布。如果首选数据布局不匹配,就在生产者和消费者之间执行适当的布局转换。
虽然高级图优化可以极大地提高 DL 工作负载的效率,但他们也只是与算子库差不多有效。目前,支持算子融合的少数 DL 框架需要算子库来提供融合模式的实现。随着定期引入更多的网络算子,可能的融合内核数量会急剧增加。当需要面对越来越多的硬件后端时,这种方法不再可持续,因为所需要的融合模式实现数量 与 必须支持的数据排布、数据类型和加速器内在函数的数量相结合。为程序所需的各种操作和每个后端手工设计算子内核是不可行的。为此,接下来提出了一种代码生成方法,可以为给定模型的算子生成各种可能的实现。
TVM 通过在每个硬件后端生成许多有效的实现并选择优化的实现,为每个算子生成高效的代码。这个过程建立在 Halide 将描述和计算规则 (或调度优化) 解耦的想法的基础上,并将其扩展为支持新的优化 (嵌套并行、张量和延迟隐藏) 和 广泛的硬件后端。
引入了张量表达式语言来支持自动代码生成,与高级计算图表示不同,张量算子的实现是不透明的,每个算子都用索引公式表达语言来描述。以下代码展示了计算转置矩阵乘法的示例张量表达式。

每个计算操作都指定输出张量的形状 和 描述如何计算它的每个元素的表达式。张量表达式语言支持常见的算术和数学运算,并涵盖常见的 DL 算子形式。该语言没有指定循环结构和许多其他执行细节,它提供了为各种后端添加硬件感知优化的灵活性。采用来自 Halide 的解耦 计算/调度原则,使用调度来表示从张量表达式到低级代码的特定映射。
通过增量应用保持程序逻辑等价的基本转换 (调度原语) 来构建调度。图5展示了在专用加速器上调度矩阵乘法的示例。在内部,TVM 应用调度转换,使用数据结构来跟踪循环结构和其他信息。然后此信息可以帮助按给定的最终调度生成低级代码。

作者的张量表达式借鉴了 Halide、Darkroom 和 TACO。为了在许多后端实现高性能,必须要支持足够多的调度原语来涵盖不同硬件后端的各种优化。图6总结了 TVM 支持的算子代码生成过程和调度原语。作者重用了有用的原语和来自 Halide 的低级循环程序 AST,并且引入了新的原语来优化 GPU 和 加速器的性能。新的原语是实现最佳 GPU 性能所必需的,也是加速器所必需的。CPU、GPU 和 类TPU加速器是三种重要的深度学习硬件。
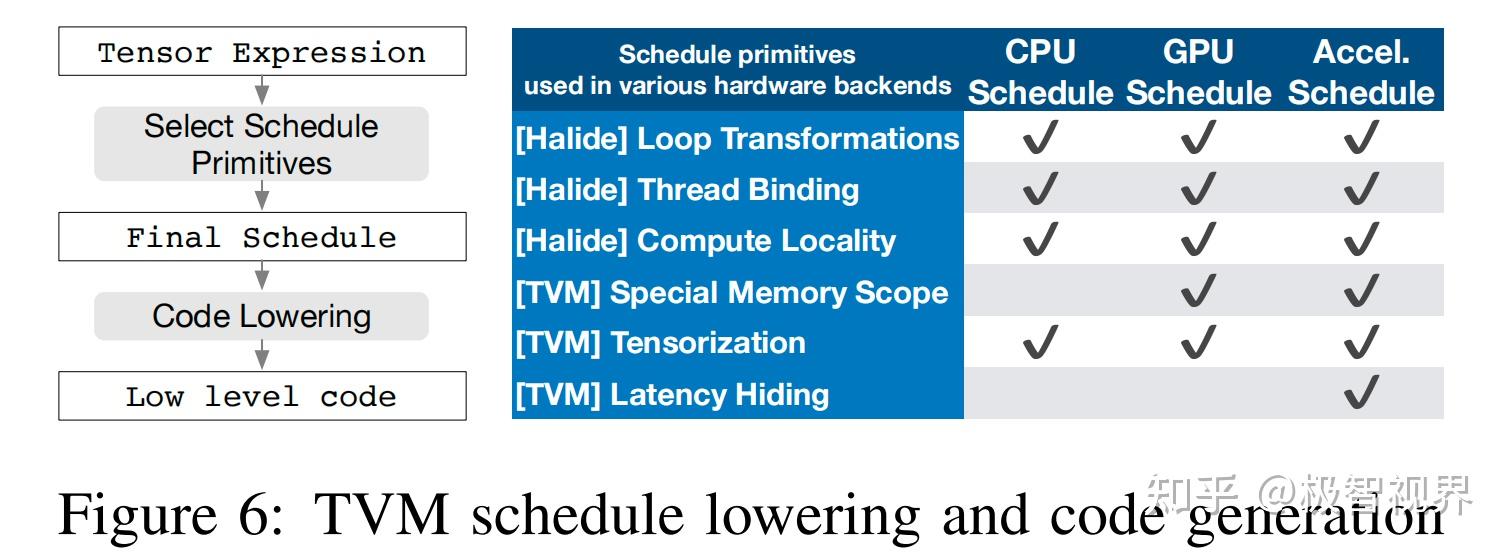
并行性是提高 DL 工作负载中计算密集型内核效率的关键。现代 GPU 提供了大规模的并行性,要求咱们将并行模式融合到调度转换中。大多数现有的解决方案都采用一种称为嵌套并行的模型,这是一种 fork-join 的形式。该模型需要并行调度原语来并行化数据并行任务;每个任务可以进一步递归地细分为子任务,以利用目标架构的多级线程层次结构 (例如 GPU 中的线程组)。将此模型称为无共享嵌套并行,因为一个工作线程无法在同一并行计算阶段查看其兄弟的数据。
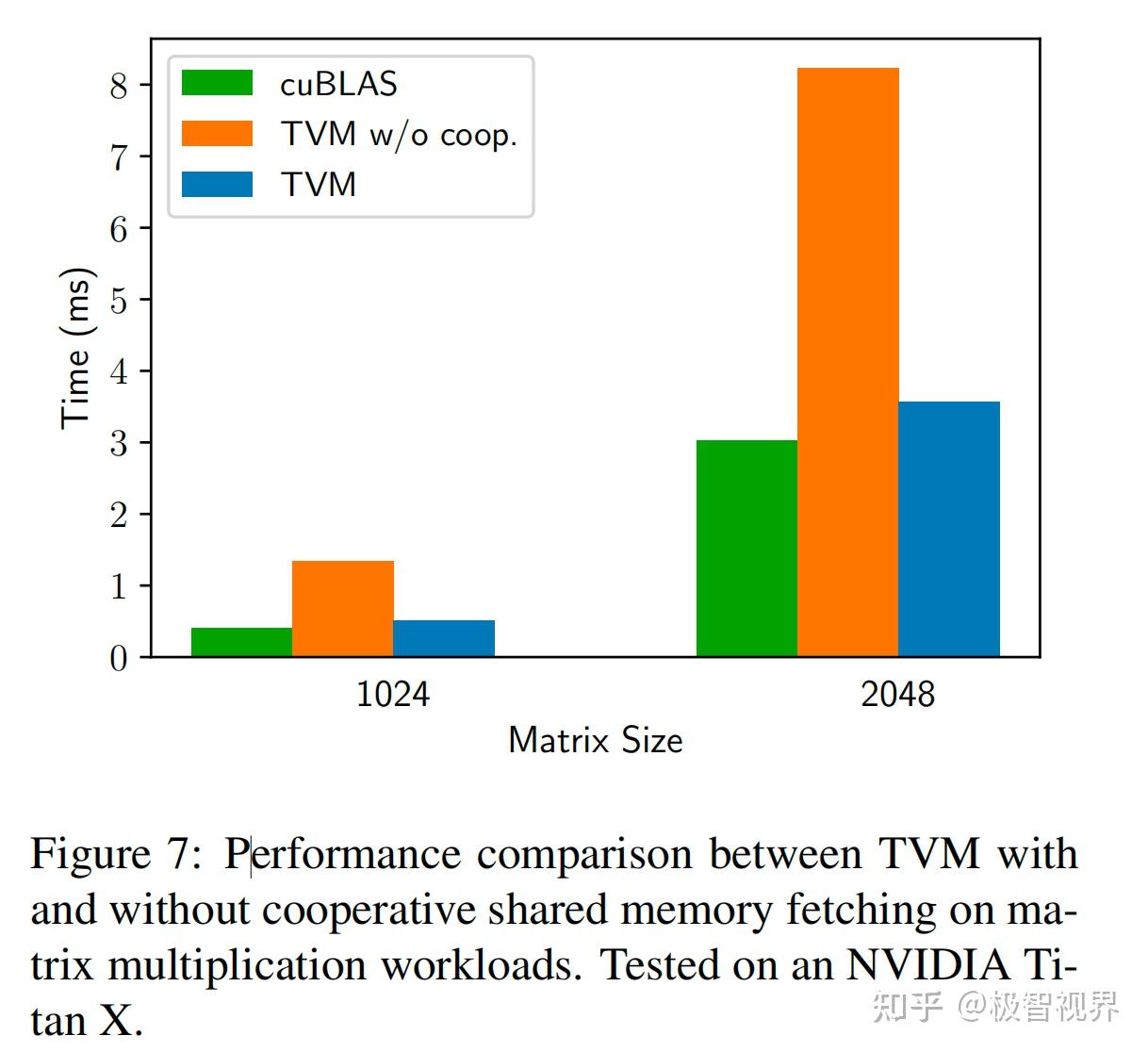
无共享方法的替代方法是协作获取数据。具体来说,线程组可以协作获取它们都需要的数据并将其放入共享内存空间中。这种优化可以利用 GPU 内存层次结构,并通过共享内存区域实现跨线程的数据重写。TVM 使用调度原语来支持这种众所周知的 GPU 优化,以实现最佳性能。以下 GPU 代码示例对矩阵乘法进行了优化。

图7展示了这种优化的影响,将内存范围的概念引入调度空间,以便可以将计算阶段 (代码中的 AS 和 BS) 标记为共享。
如果没有显式内存范围,自动范围推理会将计算阶段标记为 thread-local。共享任务必须计算组中所有工作线程的依赖关系,此外还必须正确插入内存同步屏障,以保证共享加载的数据对消费者可见。最后,除了对 GPU 有用之外,内存范围还让咱们可以标记特殊的内存缓冲区,并在针对专门的 DL 加速器时创建特殊的降低规则。
DL 工作负载具有很高的算术强度,通常可以分解为张量算子,如矩阵乘 或 一维卷积。这些自然分解导致了最近添加的张量计算原语的趋势。这些新的原语为基于调度的编译创造了机遇和挑战,使用它们可以提高性能,所以编译框架必须无缝的集成它们。这种张量化类似于 SIMD 架构的矢量化,但又有着显著差异。指令输入是多维的,具有固定或可变的长度,并且具有不同的数据排布。更为重要的是,这种原语不能是固定的,因为新的加速器有可能会出现张量指令的变体,因此需要一个可扩展的解决方法。
通过使用张量内在声明机制将目标硬件内在特性 与 调度分离,从而使张量化变得可以扩展。作者使用相同的张量表达式语言来声明每个新硬件内在行为 和 与之相关的降低规则。以下代码展示了如何声明一个 8x8 张量的硬件内在函数。

此外,引入了张量调度原语,以用相应的内在函数替换计算单元。编译器将计算模式与硬件声明相匹配,并将其降低到相应的硬件内在特性。张量化将调度与特定的硬件原语分离,从而 可以轻松扩展 TVM 以支持新的硬件架构。生成的张量调度代码符合高性能计算特性:将复杂的算子分解为一系列 micro-kernel 调用。咱们还可以使用 tensorize 原语来利用手工设计的 micro-kernel,这在某些平台上可能是有益的。例如,通过利用 bit-serial 矩阵向量乘法 micro-kernel 为移动 CPU 实现超低精度算子,这些算子对一比特或两比特宽的数据类型进行操作。这个 micro-kernel 将结果累积成越来越大的数据类型,以最大限度地减少内存占用。将 micro-kernel 表达为 TVM 固有的张量 与 非张量化版本相比 可产生高达1.5倍的加速。
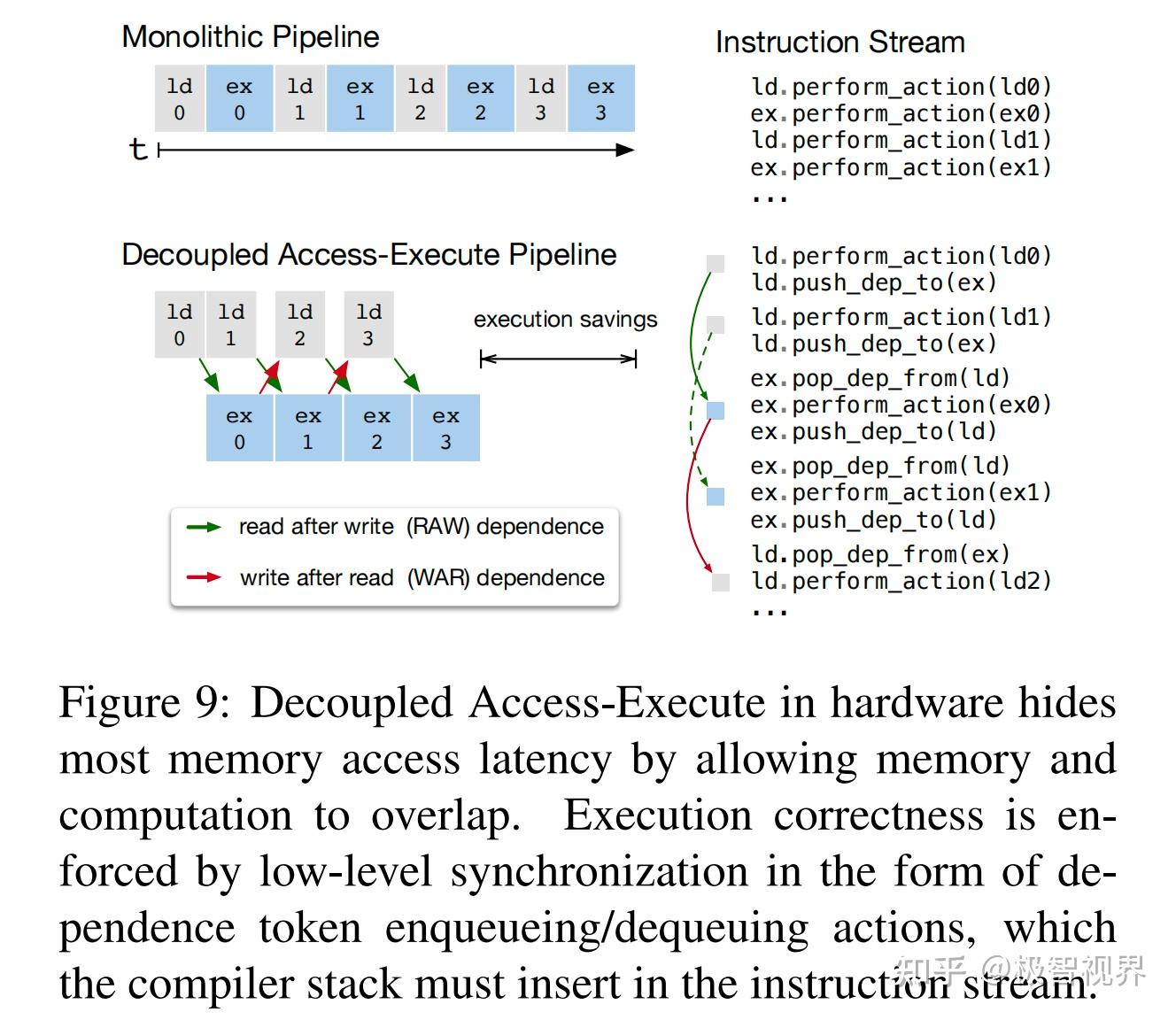
延迟隐藏是指将内存操作与计算重叠以最大限度地利用内存和计算资源的过程。它需要不同的策略,具体取决于目标硬件后端。在 CPU 上,内存延迟隐藏是通过同步多线程 或 硬件预取 来隐式实现的。GPU 依赖于许多线程的快速上下文切换。相比之下,诸如 TPU 之类的专用 DL 加速器通常倾向于使用解耦访问执行 (DAE) 架构记性更加精简的控制,并将细粒度同步的问题转移给软件。
图9显示了减少运行时延迟的 DAE 硬件管道。与单片硬件设计相比,流水线可以隐藏大部分内存访问开销,几乎可以充分利用计算资源。为了实现更加高的利用率,指令流必须增加细粒度的同步操作。没有它们,就无法强制执行依赖关系,从而导致错误执行。因此,DAE 硬件流水线需要在流水线阶段依赖于细粒度的入队/出队操作,以保证正确执行,如图9的指令流所示。
对需要显式低级同步的 DAE 加速器进行编程很困难。为了减少编程负担,引入了虚拟线程调度原语,让程序员可以指定高级数据并行程序,就像他们指定支持多线程的硬件后端一样。然后 TVM 会自动将程序降低为具有低级显式同步的单个指令流,如图8所示。该算法从高级多线程程序调度开始,然后插入必要的低级同步操作以保证每个线程的正确执行。接下来,它将所有虚拟线程的操作交付给单个指令流中。最后,硬件恢复指令流中低级同步所规定的可用流水线的并行度。
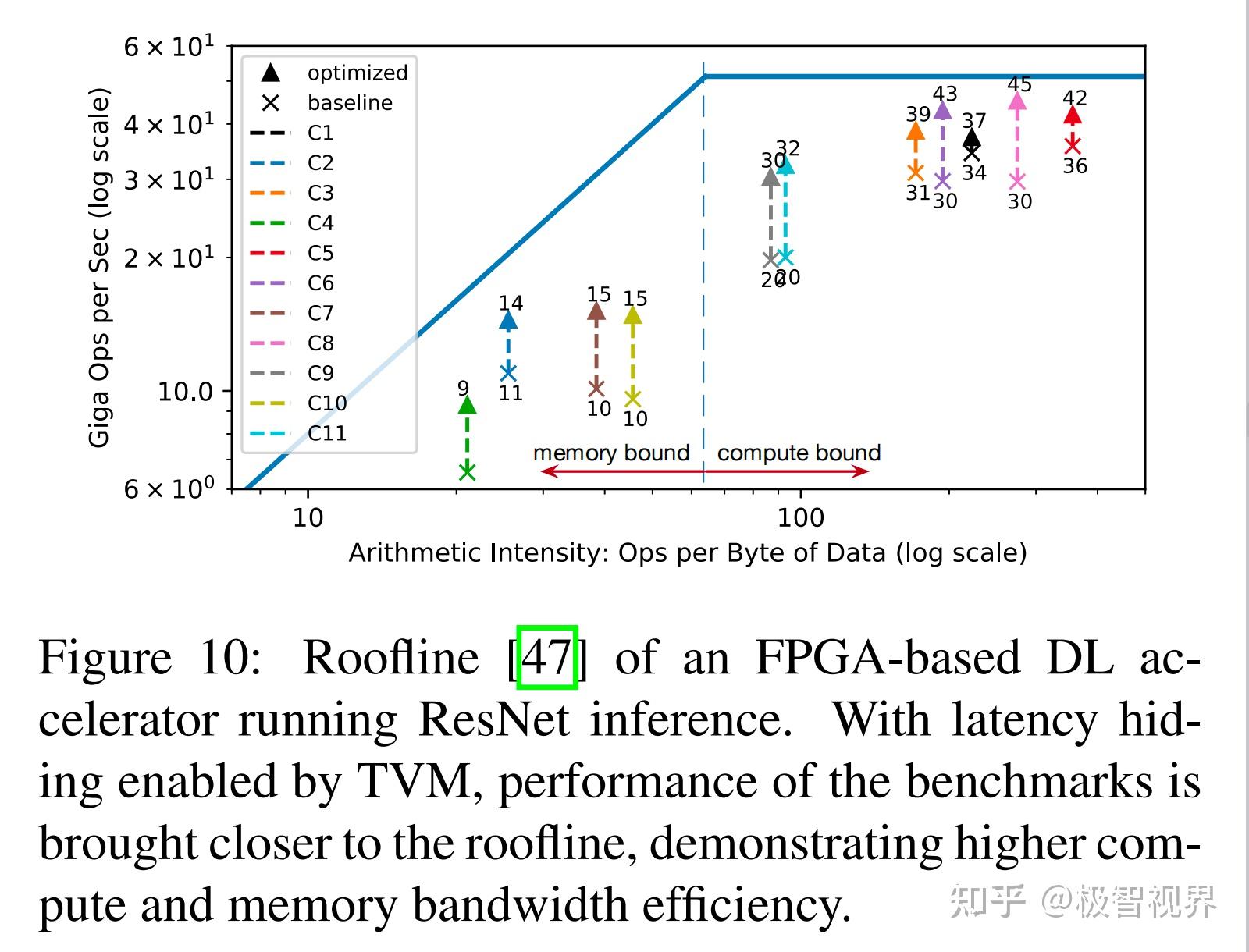
Hardware Evaluation of Latency Hiding 展示了延迟隐藏在基于 FPGA 的定制加速器设计上的有效性。在加速器上运行 ResNet 的每一层,并使用 TVM 生成两个调度:一个有延迟隐藏,一个没有。具有延迟隐藏的调度将程序与虚拟线程并行化 以进行管道并行,从而隐藏了内存访问延迟。结果在图10 中显示为 roofline图表;roofline性能图可以深入了解给定系统在不同基准测试中使用计算和内存资源的情况。总体而言,延迟隐藏提高了所有 ResNet 层的性能。峰值计算利用率从没有延迟隐藏的 70% 提高到了隐藏延迟的 88%。
鉴于丰富的调度原语集合,剩下的问题是为 DL 模型的每一层找到最佳的算子实现。在这里,TVM 为与每一层关联的特定输入形状和布局创建了一个专门的算子。这种专门的优化提供了显著的性能优势 (与针对较小的形状和布局多样性的手工代码相比),但它也提出了自动化的挑战。系统需要选择调度优化:例如修改循环顺序或优化内存层次结构,以及特定于调度的参数,例如切片大小和循环展开因子。这样的组合选择为每个硬件后端创建了算子实现的大的搜索空间。为了应对这一挑战,构建了一个具有两个主要组件的自动调度优化器:一个新配置的调度搜索器 以及 一个预测给定配置性能的机器学习成本模型。如图11展示了这些组件和 TVM 的自动优化流程。
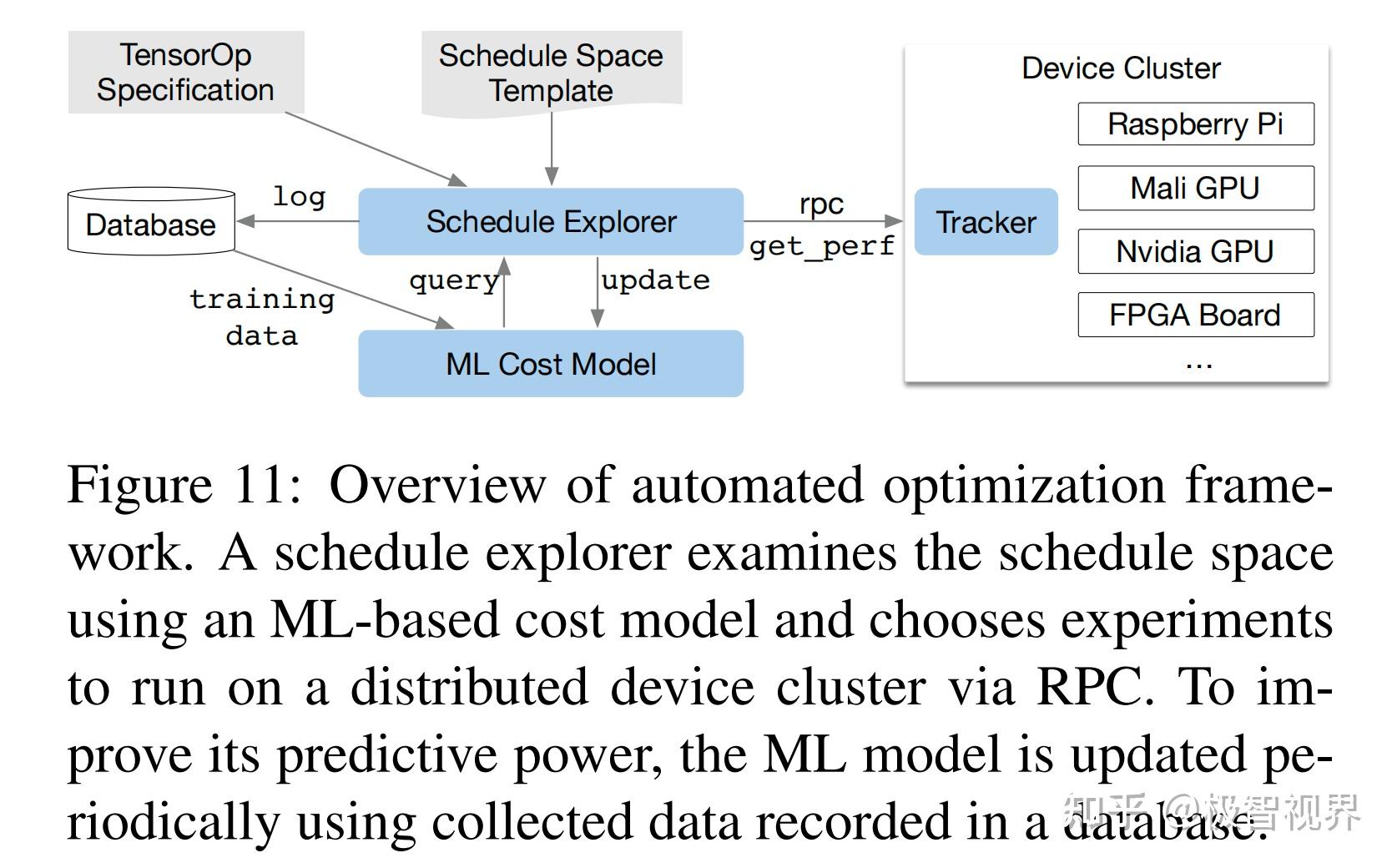
作者构建了一个调度模版规范 API,让开发人员在调度空间中声明旋钮。在指定可能的调度时,模版规范允许在必要时结合开发人员的特定领域知识。作者还为每个硬件后端创建了一个通用主模板,该模板根据使用张量表达式语言表达的计算描述自动提取可能的旋钮。在高层次上,咱们可能希望尽可能多的配置,并让优化器管理选择负担。因此 优化器必须为咱们实验中使用的真实世界 DL 工作负载搜索数十亿种可能的配置。
从大型配置空间中找到最佳调度的一种方法是通过黑盒优化,即自动调整,该方法用于调优高性能计算库。然而,自动调整需要许多实验来确定一个好的配置。
另一种方法是构建一个预定义的成本模型来指导对特定硬件后端的搜索,而不是运行所有可能性并测量它们的性能。理想情况下,一个完美的成本模型会考虑影响性能的所有因素:内存访问模式、数据重用、管道依赖性和线程模式等。不幸的是,由于现代硬件日益复杂,这种方法很繁琐。此外,每个新的硬件目标都需要一个新的 (预定义的) 成本模型。
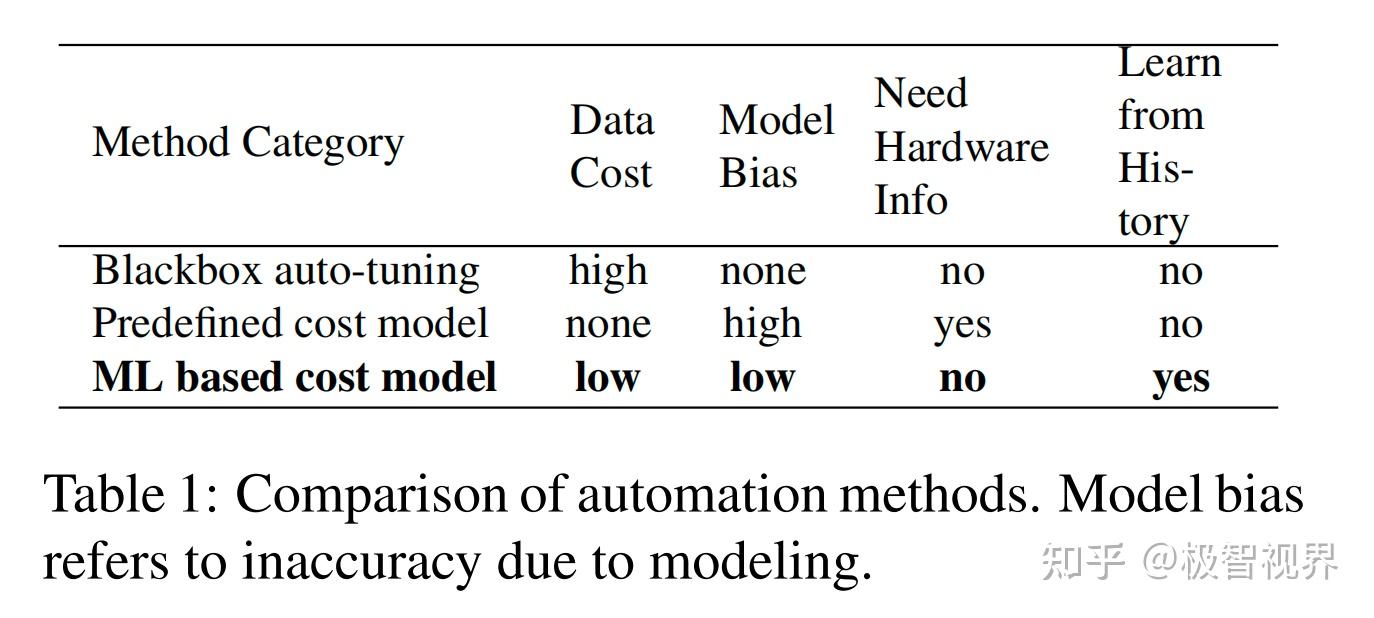
与此相反,作者采用统计方法来解决成本建模问题。在这种方法中,调度搜索器提出可以提高算子性能的配置。对于每个调度配置,使用一个 ML 模型,该模型将降低循环程序作为输入,并预测其在给定硬件后端的运行时间。该模型使用搜索期间收集的运行时测量数据进行训练,不需要用户输入详细的硬件信息。当在优化过程中搜索更多配置时,会定期更新模型,这也会提高其他相关工作负载的准确性。通过这种方式,ML 模型的质量会随着更多的试验而提高。表1总结了自动化方法之间的主要区别。基于 ML 的成本模型在自动调整和预定义成本建模之间取得平衡,并且可以从相关工作负载的历史性能数据中受益。
Machine Learning Model Design Choices 在调度搜索器选择将使用哪种 ML 模型时,咱们必须考虑两个关键因素:质量和速度。调度搜索器频繁查询成本模型,由于模型预测时间和模型调整时间而产生开销。为了可用,这些开销必须小于在真实硬件上测量性能所需的时间,根据具体的工作负载/硬件目标,这可能是几秒钟的数量级。这种速度要求将我们的问题与传统的超参数调整问题区分开来,在传统超参数调整问题中,执行测量的成本相对于模型开销非常高,并且可以使用更加昂贵的模型。除了模型的选择,咱们还需要选择一个目标函数来训练模型,例如配置预测运行时间的误差。然而,调度搜索器仅根据预测的相对顺序 (A 运行速度比 B 快) 来选择最佳候选,而不需要直接预测绝对执行时间。相反,作者采用 rank 目标来预测运行时成本的相对顺序。
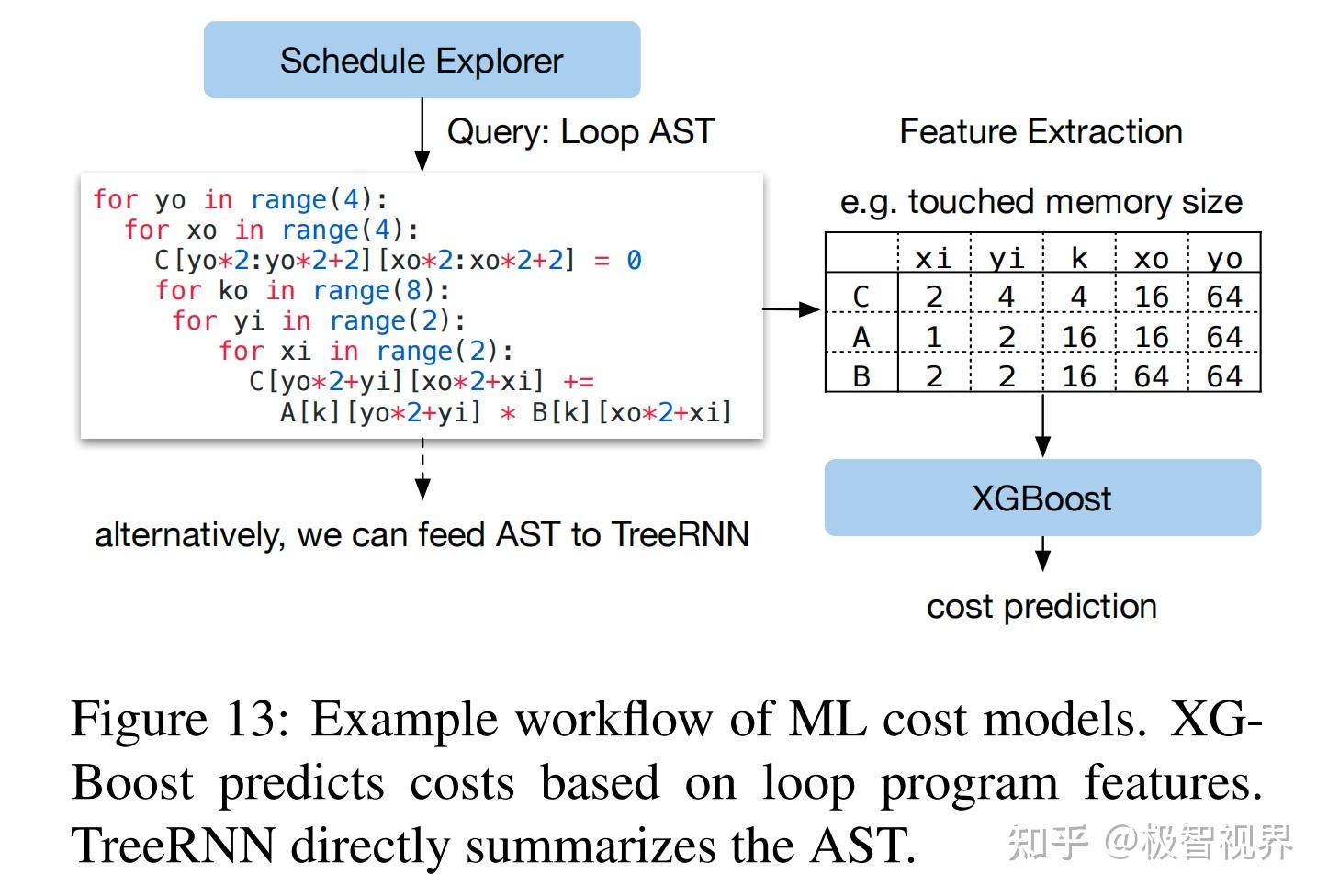
作者在 ML 优化器中实现了几种类型的模型。采用梯度树提升模型 (基于 XGBoost),它根据从循环程序中提取的特征进行预测;这些功能包括每个循环级别的每个内存缓冲区的内存访问计数和重用率,以及循环注释的 one-hot 编码,例如 vectorize、unroll 和 parallel。作者还评估了一个神经网络模型,该模型使用 TreeRNN 在没有特征工程的情况下总结循环程序的 AST。图13总结了成本模型的工作流程。
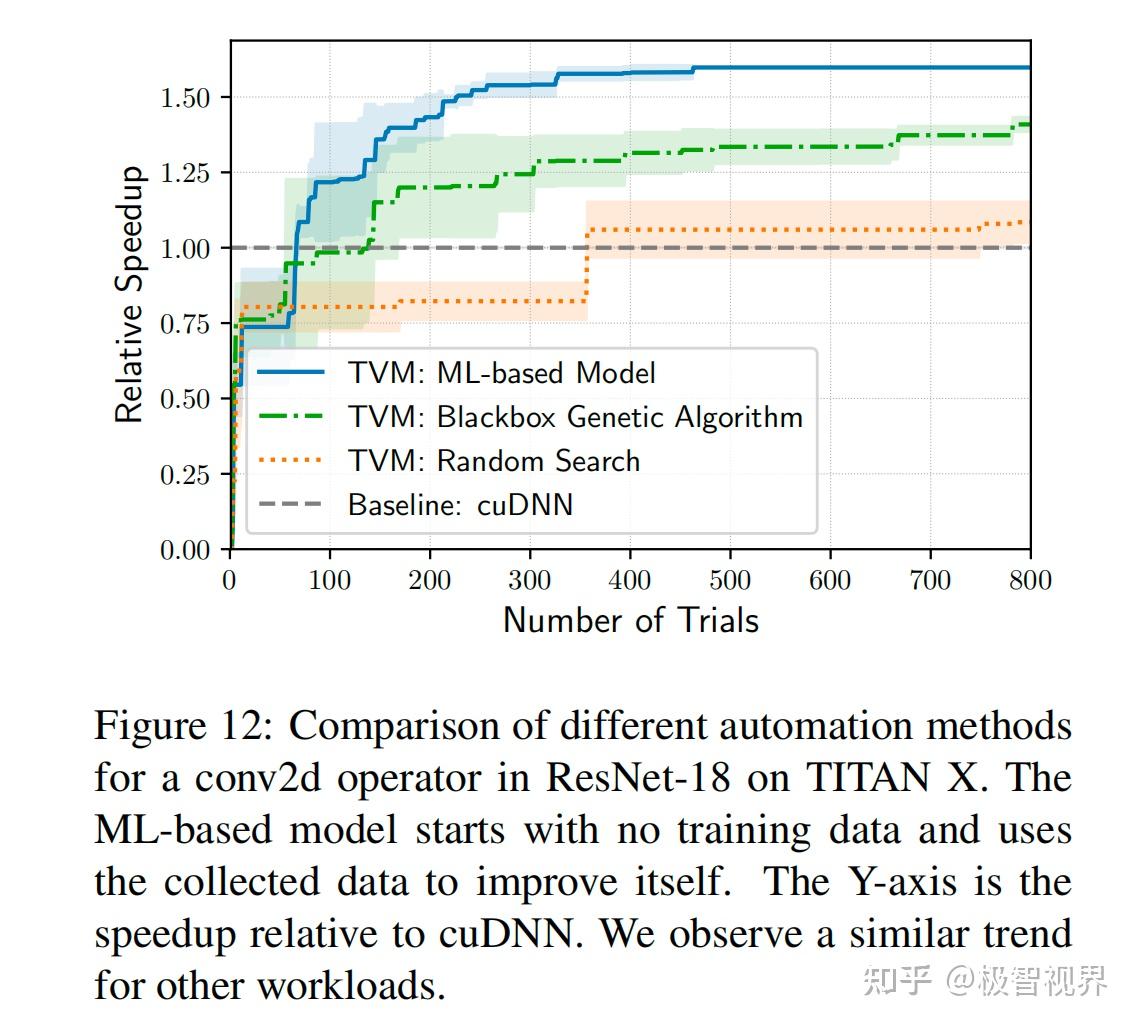
作者发现树增强和 TreeRNN 具有相似的预测质量。然而,前者的预测速度要快两倍,而且训练时间要少得多。因此,在实验中选择梯度树提升作为默认成本模型。尽管如此,作者还是相信这两种方法都是有价值的,并期待在这个问题上进行更加多的研究。平均而言,树增强模型能够在 0.67 毫秒内进行预测,这比运行实际测量要快数千倍。图12将基于 ML 的优化器与黑盒自动调整方法进行了比较;前者比后者更加快地找到了更好的配置。
一旦咱们选择了一个成本模型,我们就可以使用它来选择建议的配置,在这些配置上迭代地运行实际测量。在每次迭代中,搜索器使用 ML 模型的预测来选择一批候选者来运行测量。然后将收集的数据用作训练数据以更新模型。如果不存在初始训练数据,则搜索器会选择随机候选者进行测量。
最简单的搜索算法通过成本模型枚举并运行每个配置,选择前 k 个预测的执行者。但是这种策略再搜索空间很大时变得难以处理。相反,作者采用并行模拟退火算法。搜索器从随机配置开始,并且在每一步中,随机走到附近的配置。如果成本如成本模型所预测的那样降低,则这种转变是成功的。如果目标配置成本较高,则可能会失败 (拒绝)。这样随机游走在倾向于收敛于成本模型预测的成本较低的配置。搜索状态在成本模型更新中持续存在;咱们从这些更新后的最后一个配置继续搜索。
分布式设备池可以扩展硬件试验的运行,并在多个优化作业之间实现细粒度的资源共享。TVM 实现了一个定制的、基于 RPC 的分布式设备池,使客户端能够在特定类型的设备上运行程序。咱们可以使用此接口在主机编译器上编译程序,请求远程设备、远程运行函数,并在主机上访问相同脚本中的结果。TVM 的 RPC 支持动态上传并运行使用其运行时约定的交叉编译模块和函数。因此,相同的基础架构可以执行单个工作负载优化和端到端 graph 推理。作者的方法可以跨多个设备自动执行编译、运行和配置步骤。这种基础设施对于嵌入式设备尤其重要,因为传统上这些设备需要繁琐的手动操作来进行交叉编译、代码部署和测量。
图14展示了 TVM、MXNet、Tensorflow 和 Tensorflow XLA 在 NVIDIA Titan X 上的性能评估。
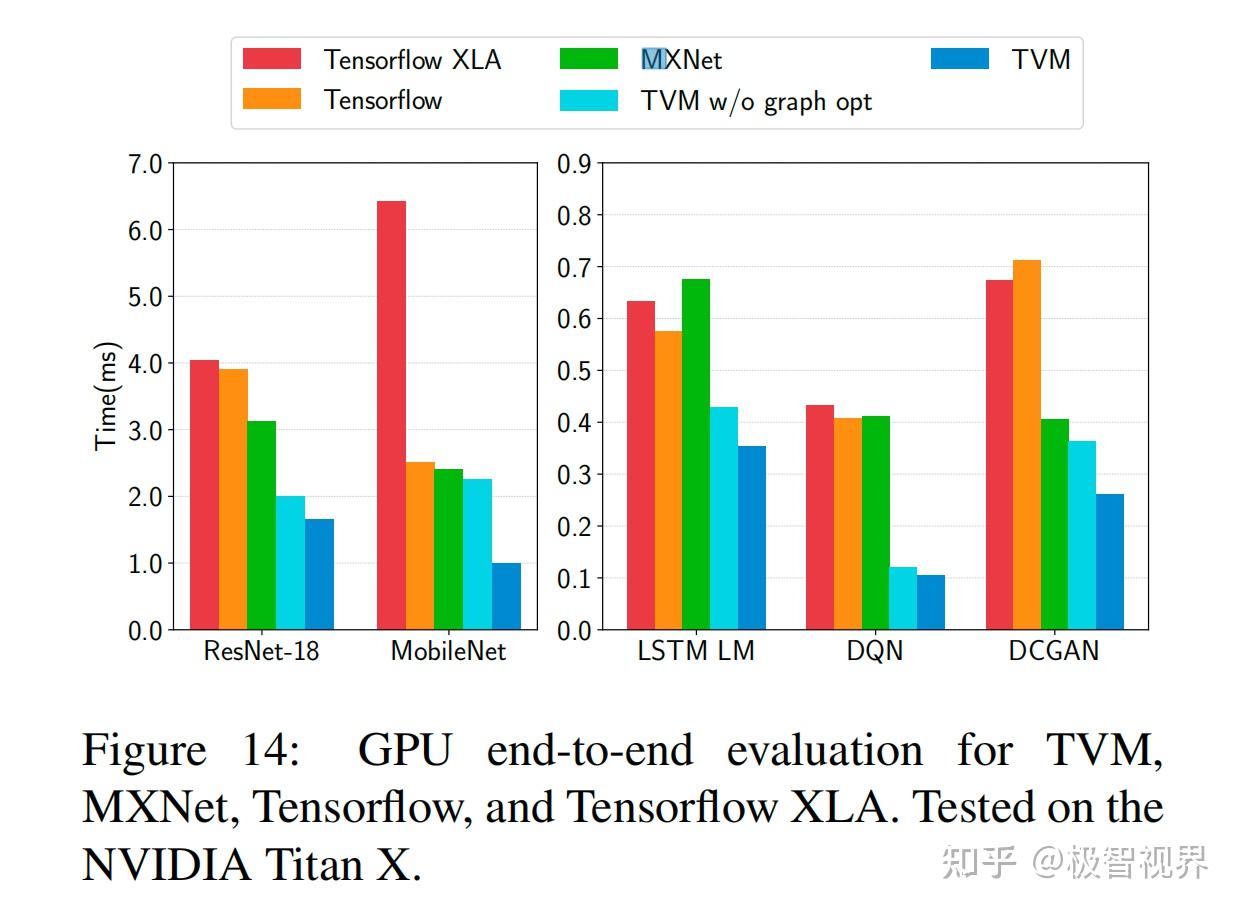
图15展示了 cuDNN、TensorComprehensions、MX Kernel、TVM、TVM PT 在 TITAN X 上对 ResNet18 中所有 conv2d 算子,和 MobileNet 中所有深度 conv2d 算子的相对加速情况。
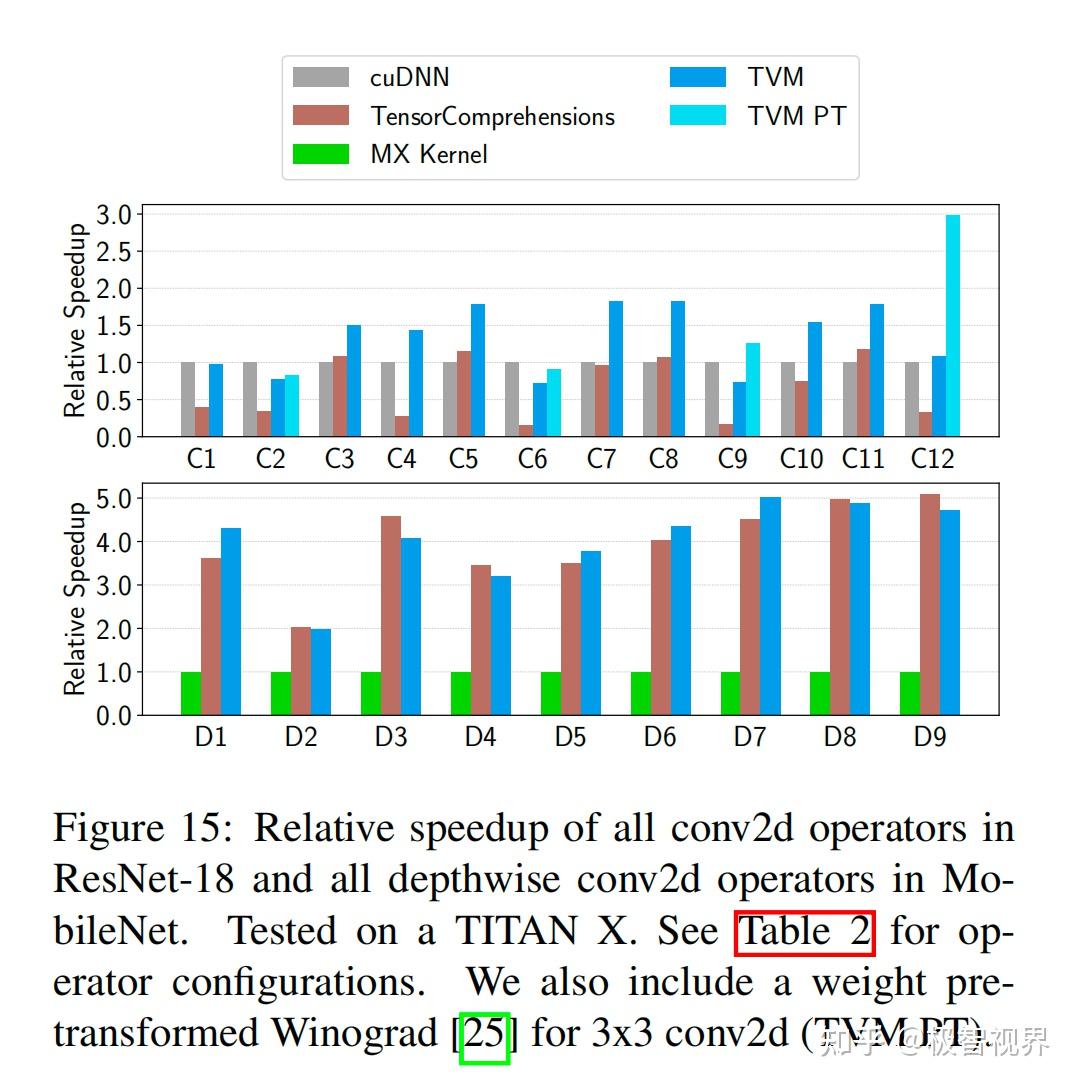
图16展示了 TVM 和 TFLite 在 ARM A53 上端到端性能评估。
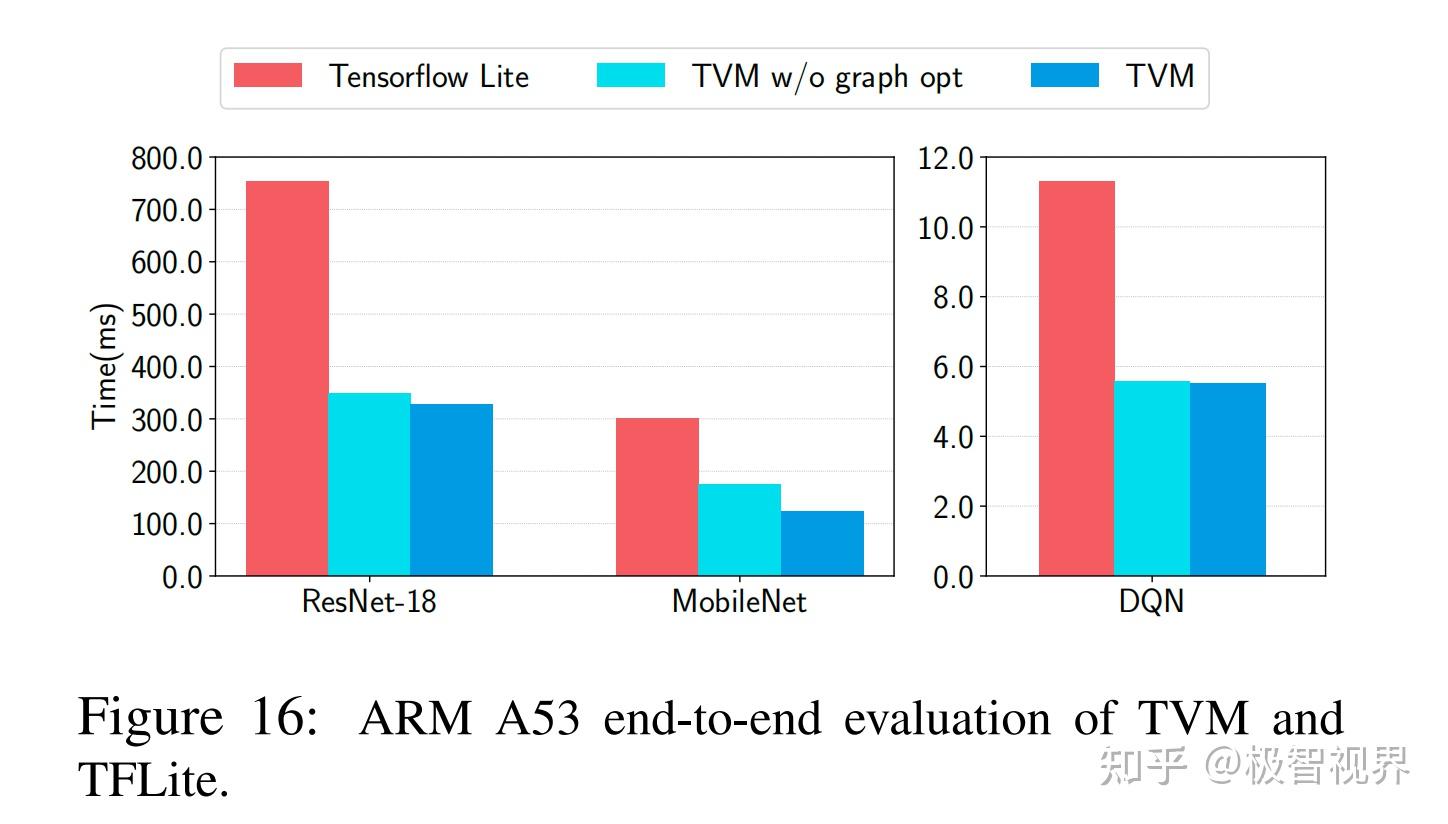
图17展示了 cuDNN、TensorComprehensions、MX Kernel、TVM、TVM PT 在 ARM A53 上对 ResNet18 中所有 conv2d 算子,和 MobileNet 中所有深度 conv2d 算子的相对加速情况。
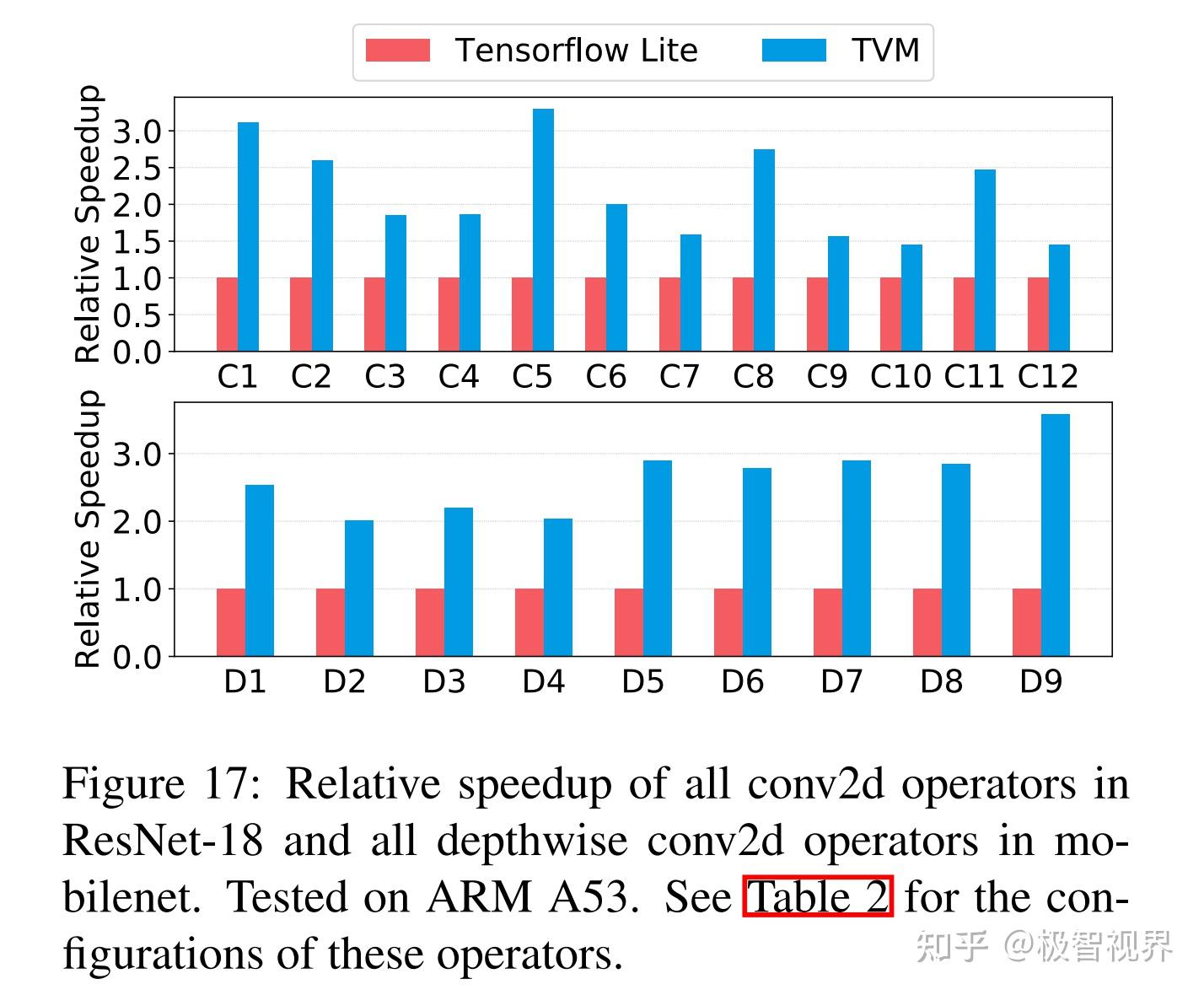
图18展示了手工优化、TVM单线程 和 TVM多线程对 ResNet 中 conv2d 算子的相对加速。
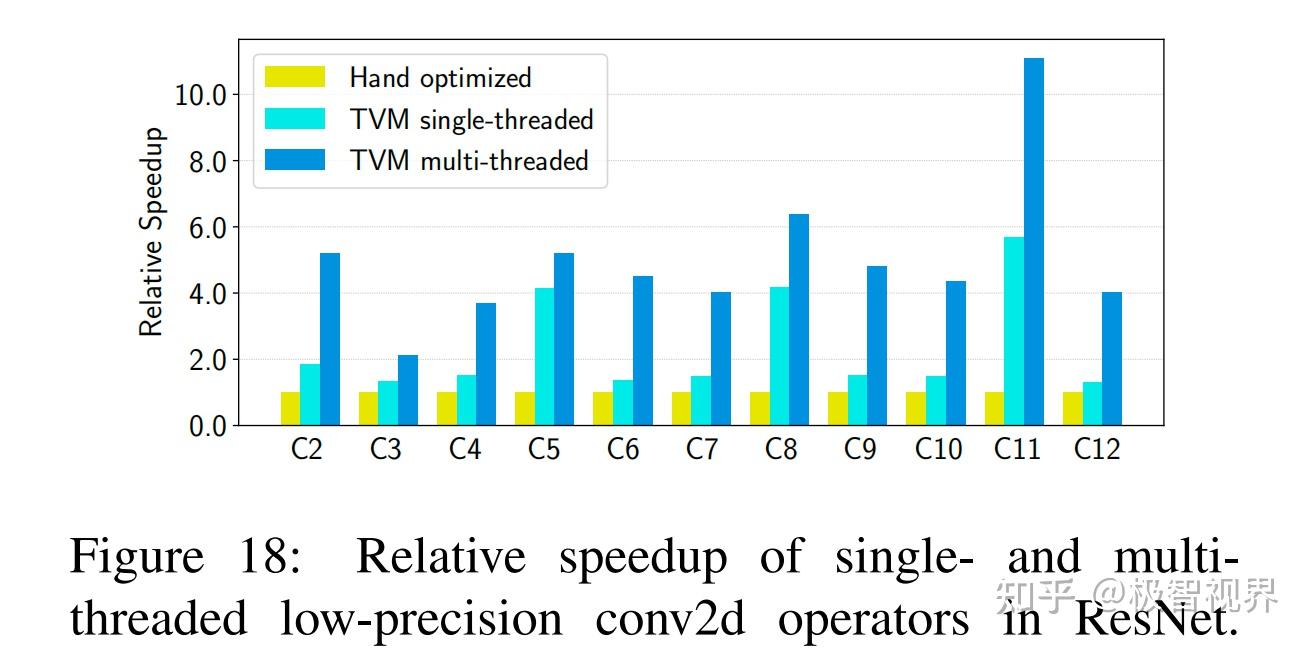
图19展示了在 Mali-T860MP4 的端到端实验结果。
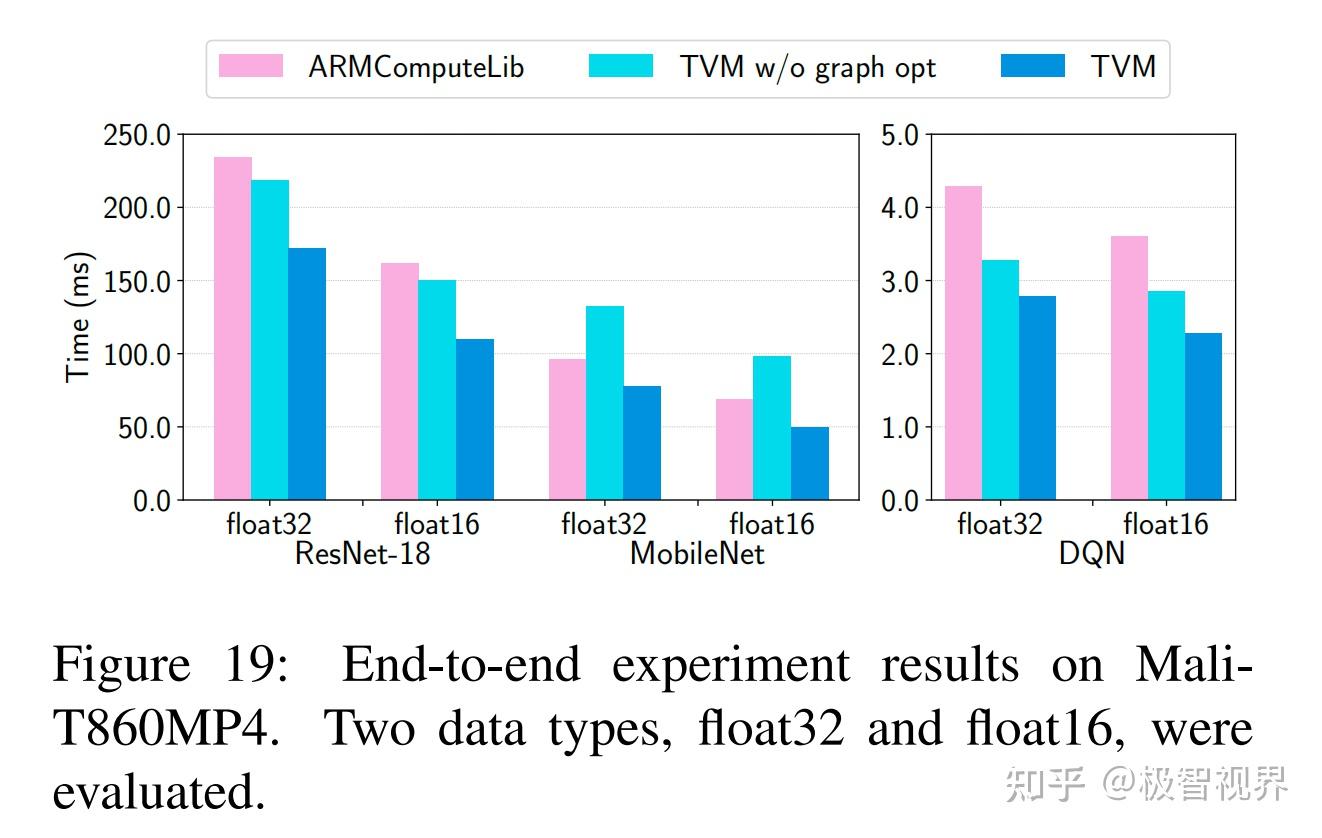
图20展示了 VDLA 硬件设计总览。
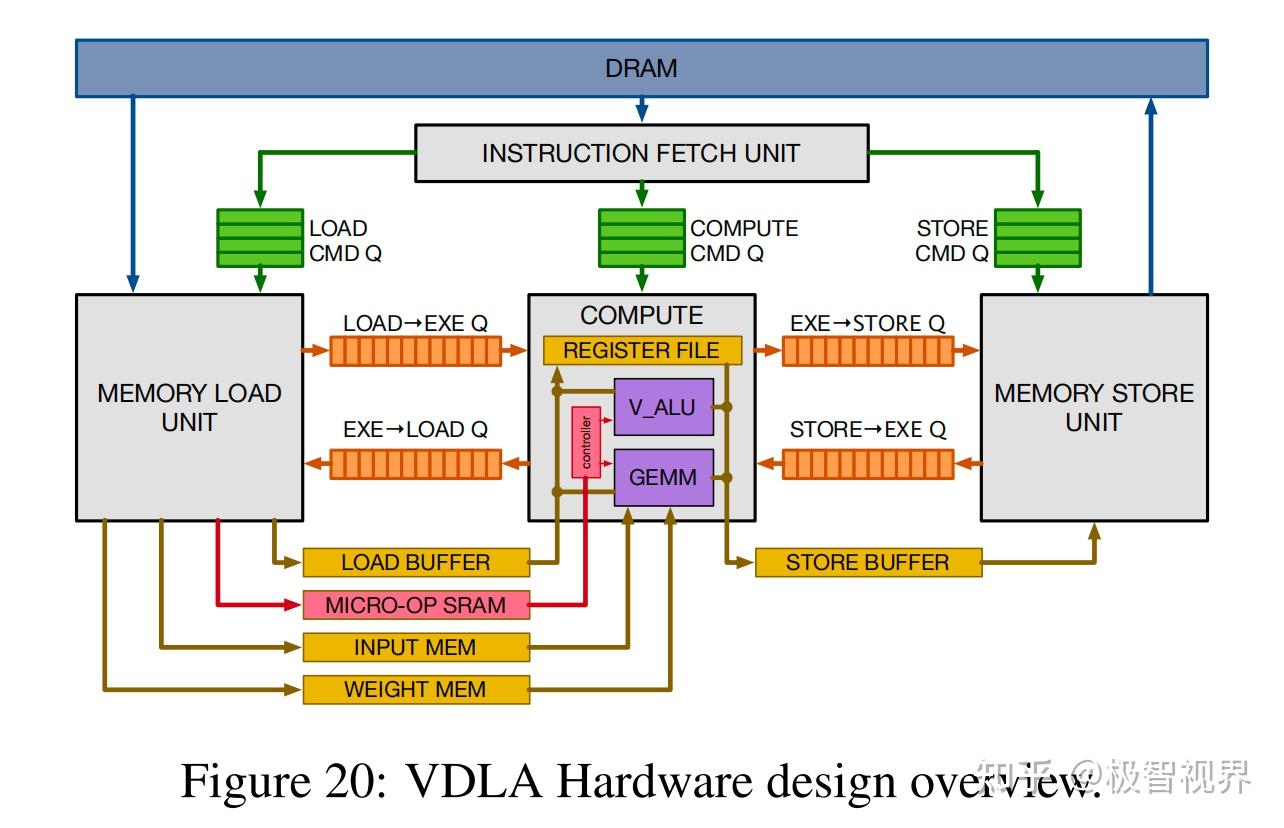
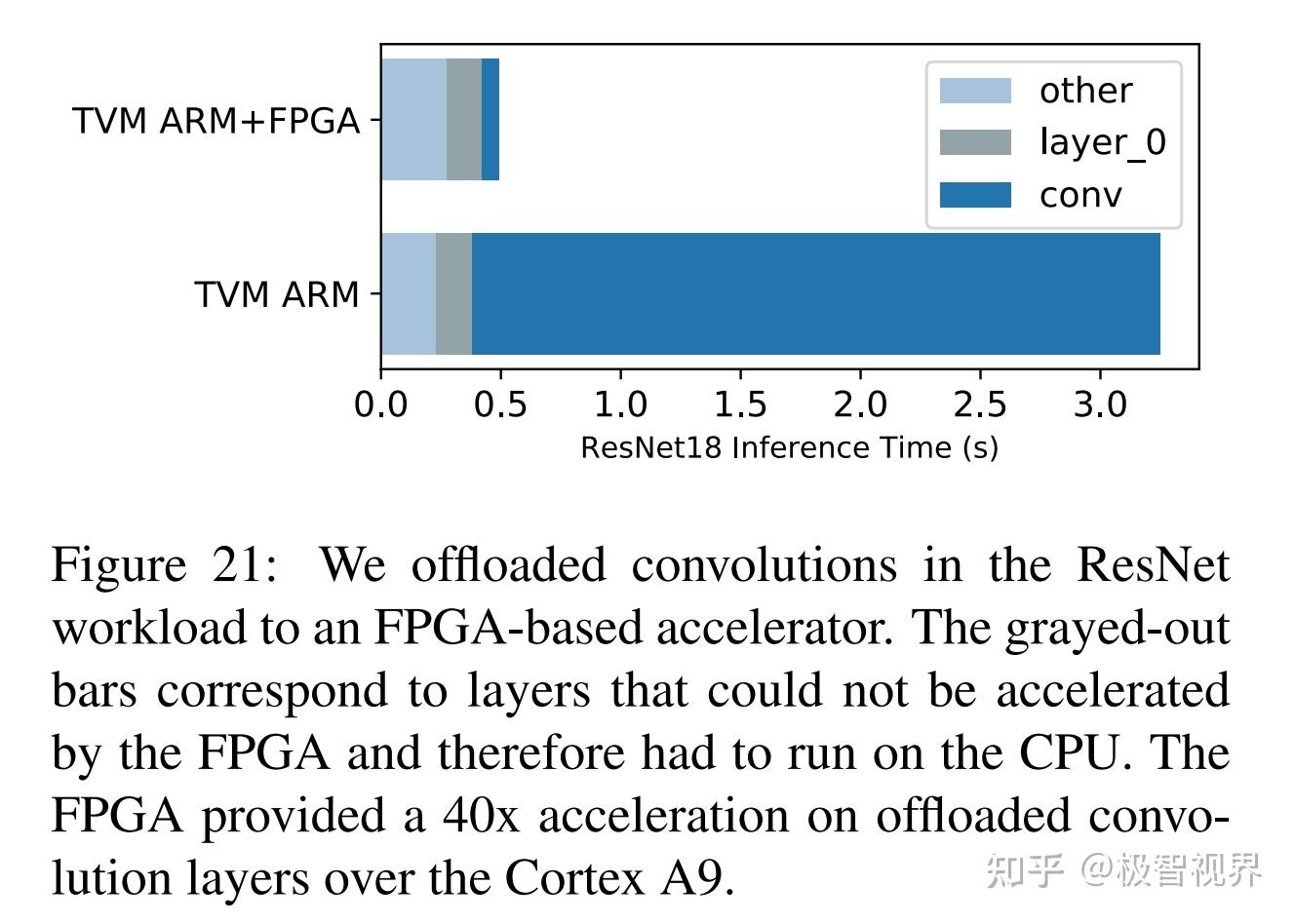
图21展示了将 ResNet 工作负载中的卷积卸载到基于FPGA的加速器上的加速效果。
作者提出了一个端到端的编译堆栈,以解决跨各种硬件后端的深度学习的基本优化挑战。提出的系统包括自动化的端到端的优化,这在以前是一项劳动密集型和高度专业化的任务。作者希望这项工作将鼓励对端到端编译方法的更多研究,并为 DL 系统软硬件协同设计技术开辟新的机会。
[1]TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.
好了,以上解读了 一种用于深度学习的端到端自动优化编译器 TVM。希望我的分享能对你的学习有一点帮助。


 首页-富联娱乐-富联中国加盟站
首页-富联娱乐-富联中国加盟站
