


今年 7 月,「深度学习教父」Geoffrey Hinton 和他的团队发表了一篇关于深度神经网络优化器的论文,介绍了一种新的优化器「LookAhead」 (《LookAhead optimizer: k steps forward, 1 step back》,https://arxiv.org/abs/1907.08610)。LookAhead 的设计得益于对神经网络损失空间理解的最新进展,提供了一种全新的稳定深度神经网络训练、稳定收敛速度的方法。
8 月,又有一篇关于优化器的论文《On the Variance of the Adaptive Learning Rate and Beyond》(https://arxiv.org/abs/1908.03265)吸引了不少研究人员的关注,这篇来自韩家炜团队的论文研究了深度学习中的变差管理,并带来了突破性进展,提出了 RAdam(Rectified Adam)优化器,也改善了网络的优化过程。
那有没有机会结合这两种方法的长处,形成一个表现更出色的优化器呢?研究员 Less Wright 就做了这个尝试,他把两者的思路集成在一起,得到了一个新的优化器,得到了很棒的结果,当然也比 RAdam 单独使用更好。
毋庸置疑,在训练的初始阶段,RAdam 能为优化器提供最棒的基础值。借助一个动态整流器,RAdam 可以根据变差大小来调整 Adam 优化器中的自适应动量,并且可以提供一个高效的自动预热过程;这些都可以针对当前的数据集运行,从而为深度神经网络的训练提供一个扎实的开头。
LookAhead 的设计得益于对神经网络损失空间理解的最新进展,为整个训练过程的鲁棒、稳定探索都提供了突破性的改进。用 LookAhead 论文作者们自己的话说,LookAhead「减少了超参数调节的工作量」,同时「在许多不同的深度学习任务中都有更快的收敛速度、最小的计算开销」。还有,「我们通过实验表明,LookAhead 可以显著提高 SGD 和 Adam 的表现,即便是用默认的超参数直接在 ImageNet、CIFAR-10/100、机器翻译任务以及 Penn Treebank 上运行」。

那么,既然两种方法是从不同的角度对深度学习的优化过程提供了改进,我们全完可以猜测两者合并以后可以起到协同作用,带来更棒的结果;也许这就是我们在寻找更稳定更鲁棒的优化方法之路上的最新一站。
在下文中,作者将会在 RAdam 介绍的基础上解释 LookAhead 的原理,以及如何把 RAdam 和 LookAhead 集成到同一个优化器(Ranger)中。在作者的实验中,训练只运行了前 20 个 epoch,模型就给出了一个让作者喜出望外的准确率;实际上这个准确率要比 FastAI 的排行榜第一名还要高出 1%。
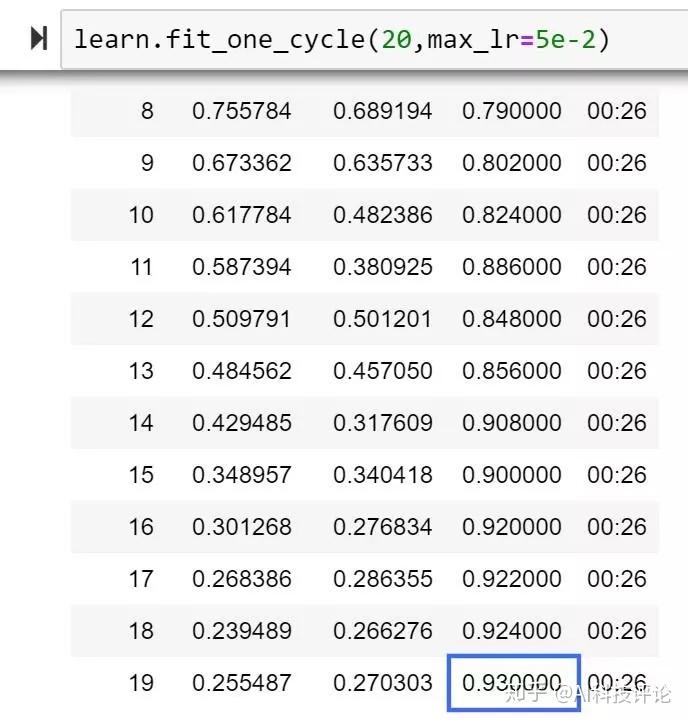

更重要的是,文中有详尽的源代码和使用信息介绍,任何人都可以运行这个 Ranger 优化器,看看能否看到稳定性和准确率的提升。
下面我们先分别认识一下 RAdam 和 LookAhead。
简单来说,RAdam 的作者们研究了为什么带有自适应动量的优化器(Adam, RMSProp 等等)都需要一个预热阶段,不然在训练刚刚启动的时候就很容易陷入不好的、可能有问题的局部最优。
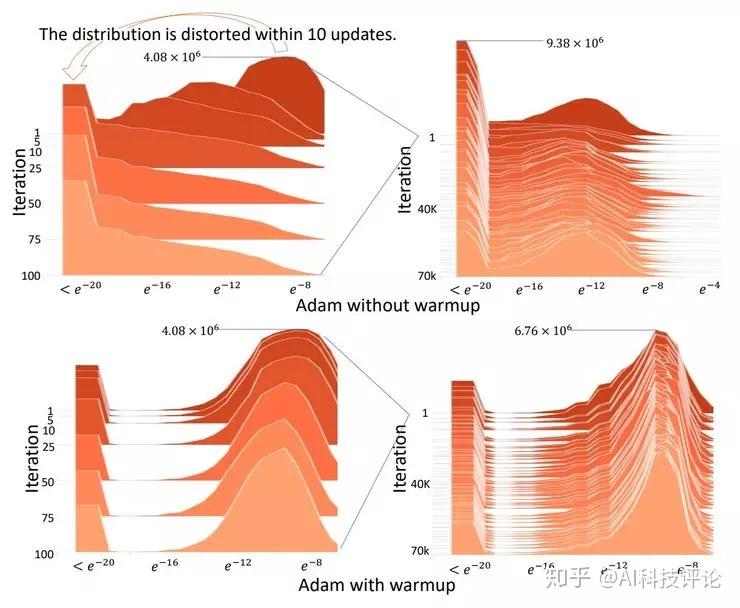
他们找到的原因是,在训练刚开始时有非常大的变动,可以说是优化器还没见到足够多的数据,没法做出准确的自适应动量选择。预热过程就可以在训练的初始阶段减小变差。根据上面这张图可以看到,没有预热阶段的时候,迭代早期的误差分布会发生剧烈变化。不过,多长的预热过程才算够需要手动调整,而且在不同的数据集上也会有所不同。
所以,RAdam 的设计思路就是采用了一个整流器函数,它可以基于实际遇到的变差计算出一个「预热启发值」。然后这个整流器可以动态地对自适应动量进行开、关或者加阻尼,避免它以全速运动,直到来自数据的变差开始稳定为止。这样的做法就避免了用人工方法执行一个预热阶段,训练过程也就自动稳定下来了。
当变差稳定下来之后,RAdam 在剩下的训练过程中基本就等效于 Adam 甚至 SGD。也所以,RAdam 只能为训练的开始阶段带来改善。
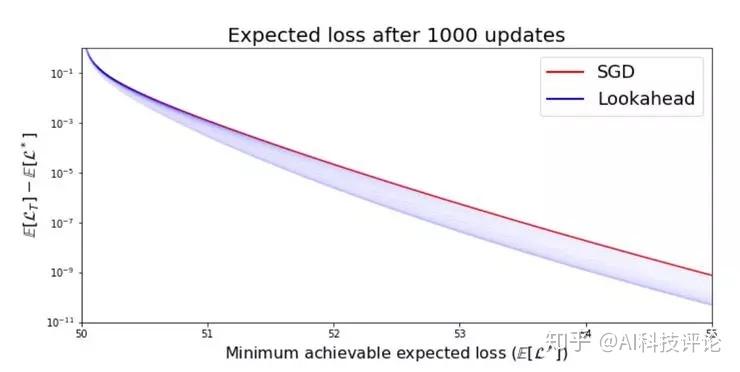
需要各位读者注意的是,虽然在 RAdam 论文中的实验结果小节里 RAdam 的表现比 Adam 好,但是如果运行非常长的时间,那么 SGD 最终会追上来,而且会得到比 RAdam 和 Adam 更高的最终准确率。
现在我们就需要转头看看 LookAhead 了,我们需要集成一种新的探索机制,能在超过 1000 个 epoch 的训练之后仍然比 SGD 表现更好。
在介绍 LookAhead 之前,我们首先需要知道,在 SGD 基础上改进而来的大多数成功的优化器都可以归为以下两类:
- 增加自适应动量,Adam、AdaGrad
- 增加某种加速机制,Nesterov 动量或 Polyak Heavy Ball
它们用这些做法来改进探索和训练过程,最终让模型收敛。
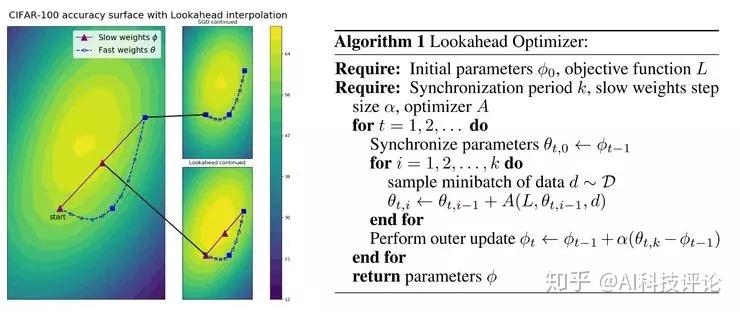
LookAhead 和它们都有所不同,它采用了一种全新的设计:会维持两套权重,并在两者之间进行内插,可以说是,它允许更快的那一组权重「向前看」(也就是探索),同时更慢的那一组权重可以留在后面,带来更好的长期稳定性。
这种做法带来的效果就是降低了训练过程中的变差,以及大大降低了对次优的超参数的敏感性(从而减少了大量尝试超参数调节的需要);同时,它在许多种不同的深度学习任务中都可以达到更快的收敛速度。可以说这是一项飞跃式的进步。
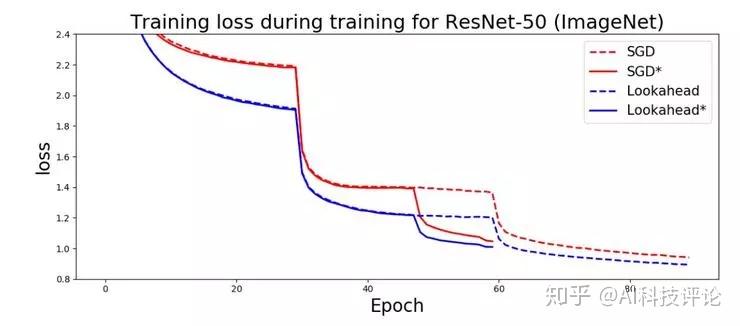
可以打个简单的比方,假想你在一个山顶区域,你周围有很多条不同的路下山,有的也许可以让你轻松到达山下,有的路则会遇到险恶的悬崖和断层。如果你孤身一人,去探索这些路就会有点麻烦,你得一条条尝试,假如选的路走不通,你很可能会卡在半路,回不到山顶、没办法试下一条路了。但是如果你有个好朋友一起,他可以在山顶等你,而且可以帮助你脱离险境的话,那么你被卡在半路的机会就小多了、找到合适的下山路的机会就大多了。
可以说 LookAhead 基本就是这样工作的,它会多存储一份权重副本,然后让那个内部的「快」优化器多探索 5 或 6 个批(在作者的 Ranger 实现中,快的优化器就是 RAdam,多探索的批的数量通过 k 参数指定)。
每经过 k 个间隔,快优化器 RAdam 多探索了 k 个批,然后 LookAhead 会计算存储的权重副本和最新的 RAdam 的权重的差,把这个差乘上 alpha 参数(默认为 0.5),然后更新 RAdam 的参数,再开始下 k 个间隔的探索。

这样做的效果就是,LookAhead 从内部快优化器(这里就是 RAdam)实现一个快速前进的均值的同时,还有一个慢一些的指数前进的均值。
快速前进有更好的探索效果,慢的那个起到一个拖拽回归的作用,也可以看作是一个稳定性维持机制 —— 一般情况下慢速前进的这个都落在后面,但也可以在快的优化器进入了一个更有潜力的下坡却又跑出去的时候把它拽回来。整个优化器可以更细致地探索整个空间,同时不需要怎么担心卡在不好的局部极值。
这种方法和上面提到的目前的两种主流方法都完全不同,然后由于它的设计提升了训练稳定性,所以它的探索速度更快、探索过程更鲁棒,探索的结果也比 SGD 更好。
在解释过 LookAhead 的工作原理以后我们可以看出来,其中的那个快优化器可以选用任意一个现有的优化器。在 LookAhead 论文中他们使用的是最初的 Adam,毕竟那时候 RAdam 还没有发布呢。

那么显然,要实现 RAdam 加 LookAhead,只需要把原来的 LookAhead 中的 Adam 优化器替换成 RAdam 就可以了。
在 FastAI 中,合并 RAdam 和 LookAhead 的代码是一件非常容易的事情,他使用的 LookAhead 代码来自 LonePatient,RAdam 则来自论文作者们的官方代码。Less Wright 把合并后的这个新优化器称作 Ranger(其中的前两个字母 RA 来自 RAdam,Ranger 整个单词的意思“突击队员”则很好地体现出了 LookAhead 能出色地探索损失空间的特点)。
Ranger 的代码开源在 https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
使用方法:
1、把 ranger.py 拷贝到工作目录下
2、import ranger
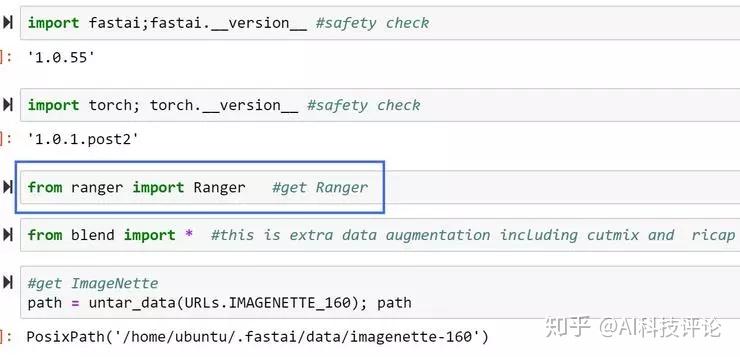
3、创建一个 partial,为 FastAI 调用 Ranger 做准备,然后把学习者的 opt_func 指向它

4、开始测试吧!


LookAhead 中的参数:
- k - 它控制快优化器的权重和 LookAhead 中的慢优化器的权重协同更新的间隔。默认值一般是 5 或者 6,不过 LookAhead 论文里最大也用过 20。
- alpha - 它控制根据快慢优化器权重之差的多少比例来更新快优化器的权重。默认值是 0.5,LookAhead 论文作者 Hinton 等人在论文里给出了一个强有力的证明,表示 0.5 可能就是理想值。不过大家也可以做自己的尝试。
- 他们也在论文中指出,未来一个可能的改进方向是根据训练进行到不同的阶段,规划使用不同的 k 和 alpha 的值。
最近刚好有两支团队各自在深度神经网络的优化问题上做出了提高速度和稳定性的成果,而且巧的是他们的成果是可以协同工作、带来更好的结果的。结合两者得到的新优化器 Ranger 带来了非常优异的表现,刷新了 FastAI 的在 ImageNet 上运行 20 个 epoch 的准确率排行榜。
尽管其中的 k 参数和 RAdam 使用的学习率这两个参数还有探究和调整的空间,但毕竟已经大大降低了超参数调整的工作量,也可以轻松带来更好的结果。大家可以立刻把这个方法投入使用。
- LookAhead 论文地址:《LookAhead optimizer: k steps forward, 1 step back》
- https://arxiv.org/abs/1907.08610v1
- LonePatient 的 LookAhead 实现:
- https://github.com/lonePatient/lookahead_pytorch/blob/master/optimizer.py
- RAdam 论文地址:
- https://arxiv.org/abs/1908.03265
- RAdam 论文作者的 RAdam 实现:《On the Variance of the Adaptive Learning Rate and Beyond》
- https://github.com/LiyuanLucasLiu/RAdam
科技评论文章链接:RAdam、LookAhead 双剑合璧,打造最强优化器

 首页-富联娱乐-富联中国加盟站
首页-富联娱乐-富联中国加盟站
