


【前言】: 优化问题一直是机器学习乃至深度学习中的一个非常重要的领域。尤其是深度学习,即使在数据集和模型架构完全相同的情况下,采用不同的优化算法,也很可能导致截然不同的训练效果。
adam是openai提出的一种随机优化方法,目前引用量已经达到4w+,在深度学习算法优化中得到广泛的使用,是一种高效的优化算法。该算法是在梯度下降算法(SGD)的理念上,结合Adagrad和RMSProp算法提出的,计算时基于目标函数的一阶导数,保证了相对较低的计算量。adma的优点如下:参数更新的大小不随着梯度大小的缩放而变化;更新参数时的步长的边界受限于超参的步长的设定;不需要固定的目标函数;支持稀疏梯度;它能够自然的执行一种步长的退火。
ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION1 Gradient Descent(梯度下降算法)
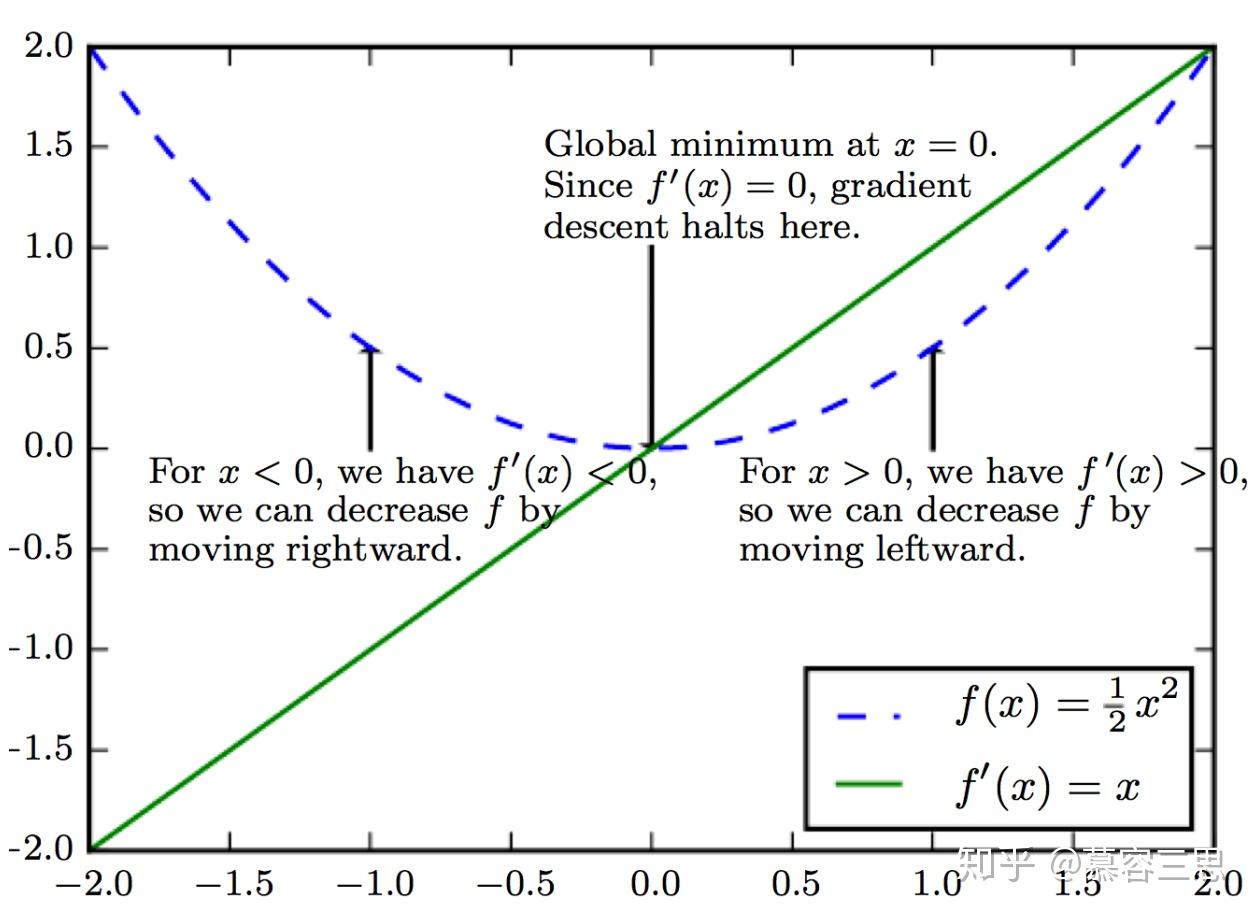
优化问题中大部分问题都可以转化为求解一个标量的目标函数的最大值或最小值。当
对其参数
可微时,可采用梯度下降法进行求解。梯度下降法通过向当前位置梯度的负方向移动以实现最小化损失函数。
即最小化损失函数:
梯度更新如下:
优点: 针对凸函数 可以得到全局最优解;
缺点: 1> 收敛速度慢,
2> 要求目标函数是stationary(固定的), 训练数据需要一次性填到内存中,因此需求内 存大,当数据量大时,无法使用GD;
2 Stochastic Gradient Descent(随机梯度下降)
随机梯度下降顾名思义,就是在梯度下降基础上增加了随机性,即目标函数可以是随机的。目标函数可以使用minibatch中的样本计算得到,其中minibatch为在总样本中随机采样的样本。随着采样的不同,目标函数也是随机变化的。这可以有效的解决梯度下降的内存问题。
具体算法流程如下:
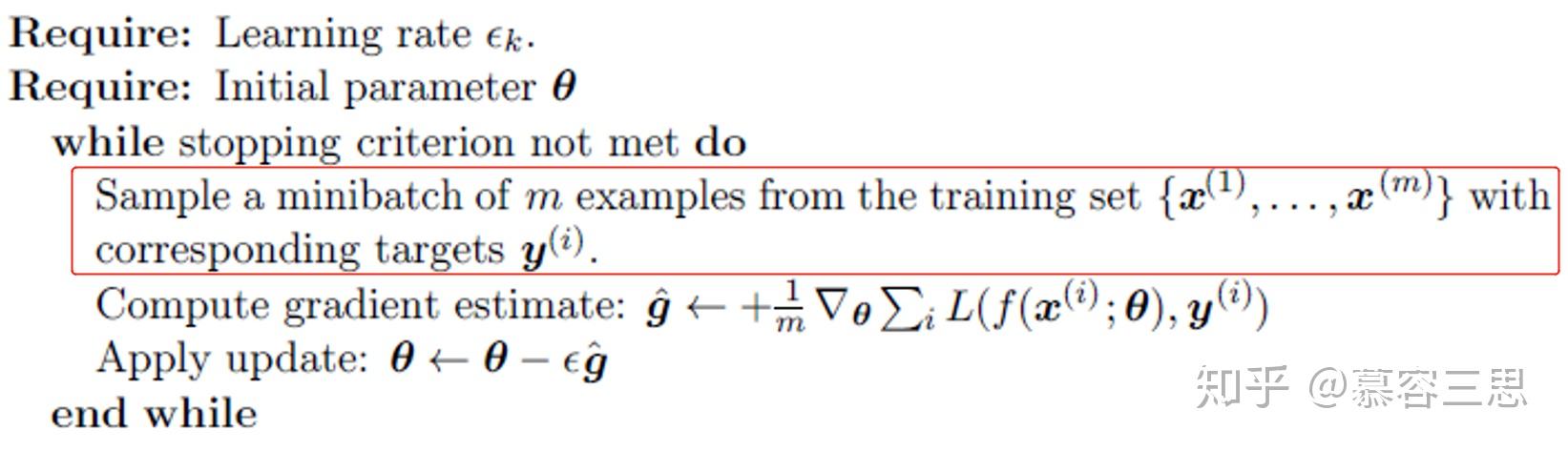
相对梯度下降算法,增加了采样过程,如标红位置。
优点:1> 通过调节采样数据的大小,易于使用有限的内存;
2> 相对于GD算法,收敛更快;
缺点:1> 训练不稳定;
2> 学习率难以选择;(学习率太小,梯度下降的步伐比较慢,训练的时间长;学习率太大,在凸函数最优解位置会来回震荡,难以收敛。所以一般随着训练不断的降低学习率)
3 SGD with Momentum
SGD是一种非常流行的优化策略,但它可能会收敛很慢。Momentum使用动量的方式加速了学习过程,尤其是遇到:损失函数高曲率情况,梯度很小但是相对稳定,噪声梯度等情况。其更新公式为:
其中 为t时刻参数的梯度,即
(后边的
定义均为t时刻的梯度)。
具体算法流程如下:

Momentum算法累积过去梯度的移动平均值,并在该方向上移动,同时增加了指数衰减。如标红位置。所述的移动平均值代表的是当前的速度v,假设以单位质量做梯度下降,则动量momentum的概念就是:质量*速度=1*v。其中超参数 决定了指数衰减。
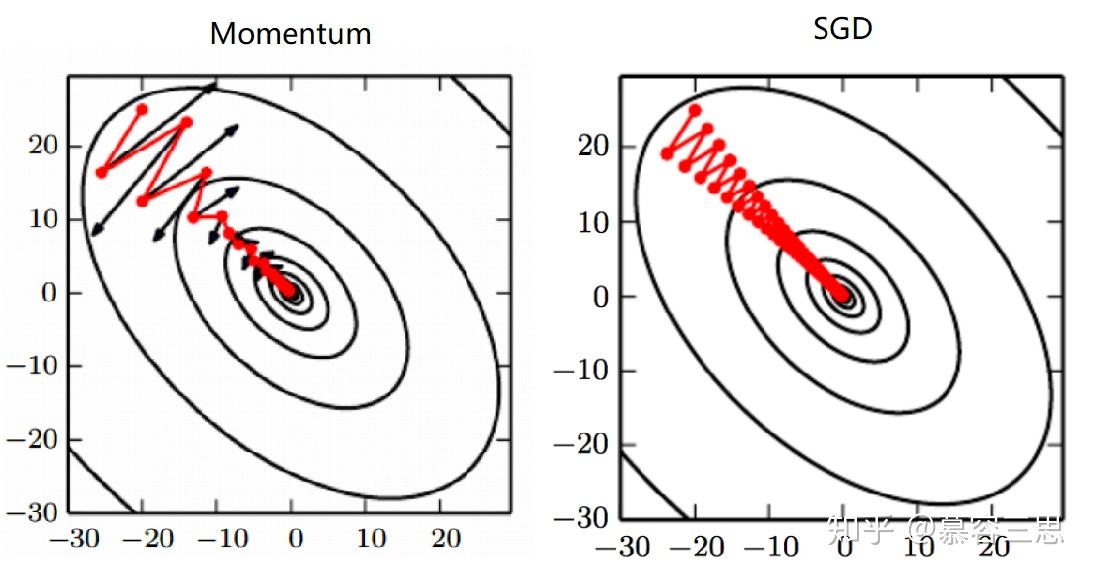
如上图所示,左侧为Momentum,它在当前时间部更新梯度时会增加之前时间部的指数加权值,从而加速收敛。
优点:相对SGD,收敛速度大幅加快;
缺点:相对adma等算法,收敛速度仍不够快
4 Nesterov Momentum(涅斯捷罗夫Momentum)
Nesterov Momentum是Momentum算法的一个变种,该方法在梯度计算之前,使用v对参数 进行更新,可以理解为在标注动量的基础上增加了一个修正因子。
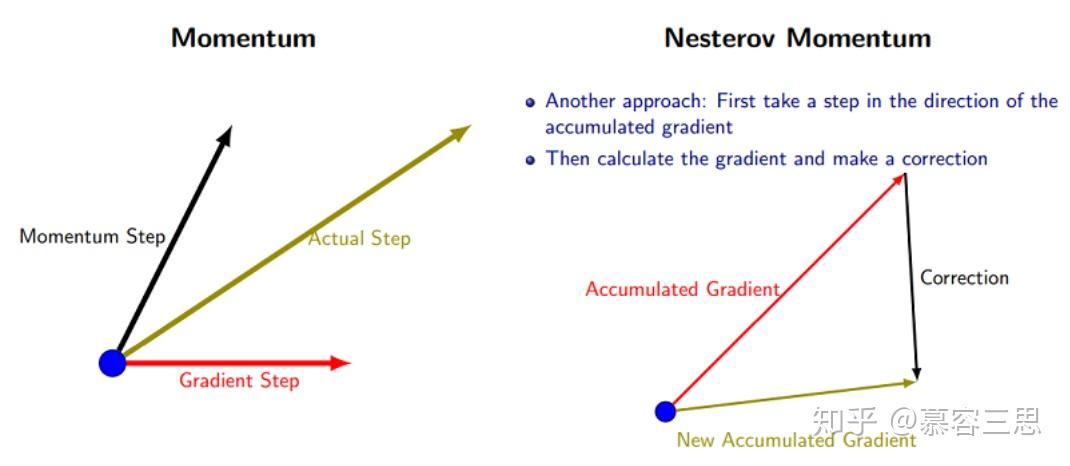
其算法流程如下,增加了标红部分:

在实际算法计算中我们用如下公式更新,以加快更新速度。具体推导略。
优点:理论上有更快的收敛速度
不足:实际收敛速度提高不大
5 Adagrad
通常,我们在每一次更新参数时,对于所有的参数使用相同的学习率。而AdaGrad算法的思想是:每一次更新参数时(一次迭代),不同的参数使用不同的学习率。AdaGrad 的公式为:
其中 常取1e-7,用于防止分母为0.
具体算法更新流程:

优点:1. 理论上有更快的收敛性。对于梯度较大的参数, 相对较大,则
(这个式子代表时刻t的真实学习率)相对较小,其对应的真实学习率较小;对于梯度小的参数则效果相反。这样可以是参数在平缓的地方下降稍微快些,不至于徘徊不前。
2. 该算法在稀疏梯度上有较好的效果
缺点:实际使用时,会导致过小或过大的真实学习率。如由于累积了梯度的平方,会越来越大,致使
;或当
非常小时,
将很大。
6 Adadelta
adadelta是在adagrad基础上改进的,解决了adagrad两个问题:1>随着训练真实的学习率会不断减小,2>需要手动选择全局的学习率。即Adadelta利用了指数加权平均的概念只累积过去 w窗口的梯度。(指数加权平均可自行百度
)
具体算法流程如下:

7 RMSprop
这个算法也是对adagrad的一个修正,在adagrad的基础上引入了指数加权的概念,是平方梯度的更新只累积窗口大小的时间步的梯度。具体更新如下:
具体算法流程如下:

优点:收敛速度快,是目前深度学习经常采用的方法之一;
1 算法结构
Adam算法的结构如下,其算法主要是在REMSprop的基础上增加了momentum,并进行了偏差修正。如下图算法中的 可理解为momentum,
可理解为梯度变化的方差,他们分别是
的一阶和二阶矩估计。

其中默认值设置α=0.001,β1?=0.9,β2?=0.999,ε=10?8。
作者指出红框中最后三行可以修改如下,从而提高算法效率。
推导过程如下:
在t时刻有效的步长为: ,则它存在两个上界,因此可以保证adam不会在某个时间步的迭代过程中更新跨度太大,导致无法收敛:
作者做了个比喻,即将 比喻成信噪比(SNR),SNR随着训练通常会逐渐减小直至趋于0,从而导致有效步长的越来越小,从而实现步长的自动退火。
同时有效步长 ?t 也不受梯度 尺度缩放的影响。
。
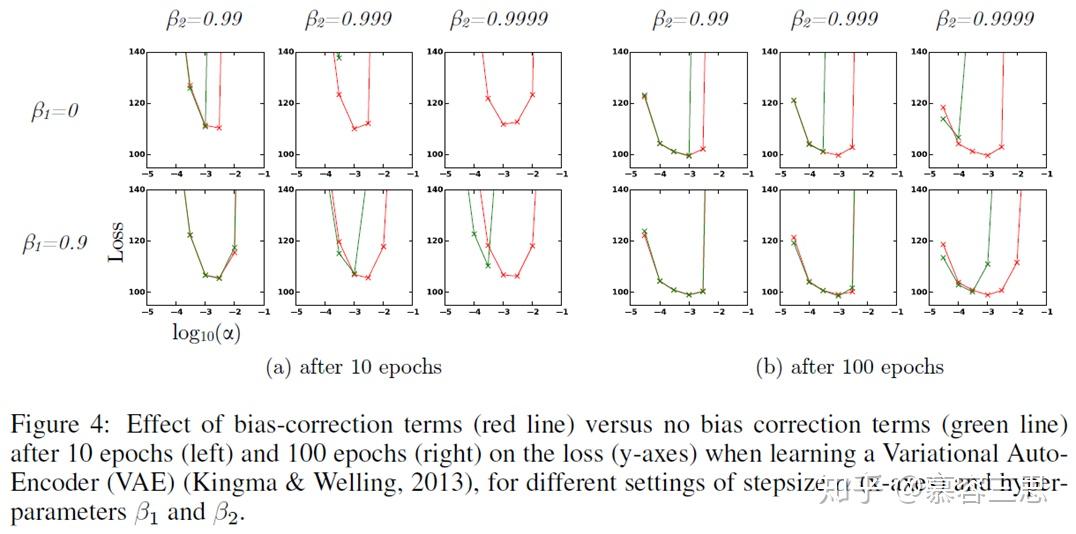
2 偏差修正(BIAS CORRECTION)
上述算法中 和
在计算指数加权平均值时,都会初始化赋值为0,导致矩估计是偏向于0的,在特别是最初的时间步或衰减率
较小的时候。因此adam对二者都进行了修正。
以为例,在时刻t,其可以表示为:
.
则计算 和 二阶矩估计
之间的关系。
其中 代表
和
之间的偏差。 我们通过指数加权平均计算出的为
,我们需要的是二阶矩估计
,因此需要除以
。
3 收敛性证明
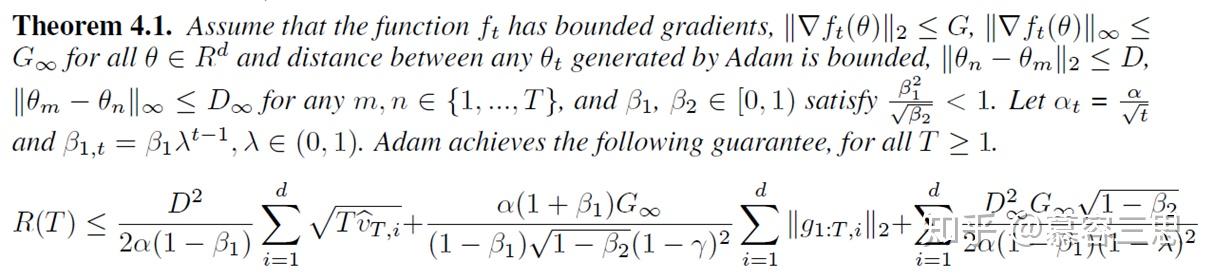
4 AdaMax
作者在Adam基础上做了扩展,adam的梯度更新规则都是反比于梯度的L2范数,即
那么能否把L2范数拓展到Lp范数? 作者给出了如下假设:
这种变体当p比较大时会出现不稳定的情况。但当 时,会有一个简单并稳定的算法,求解过程如下。

算法的整体流程:

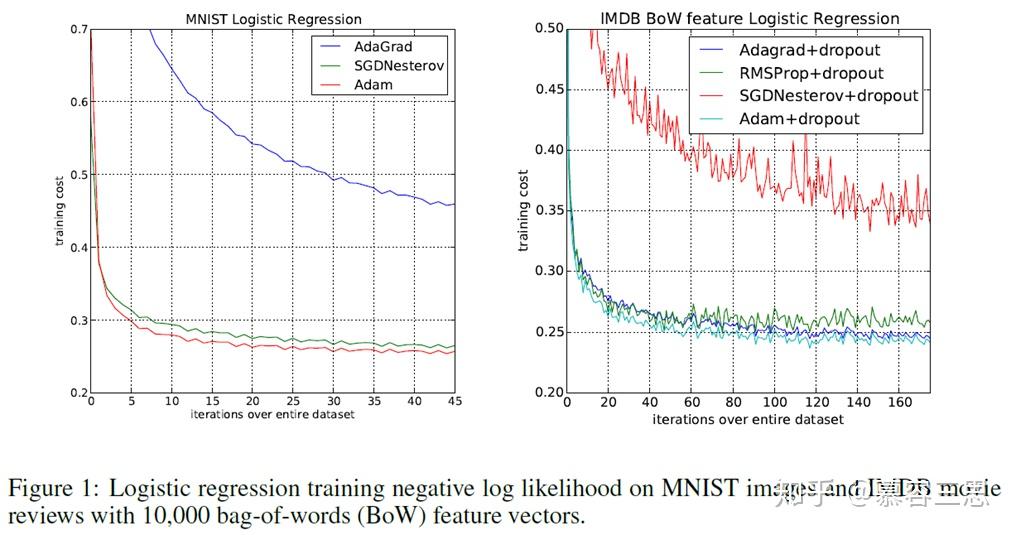
1 Logistic Regression(minist和IMDB影评)
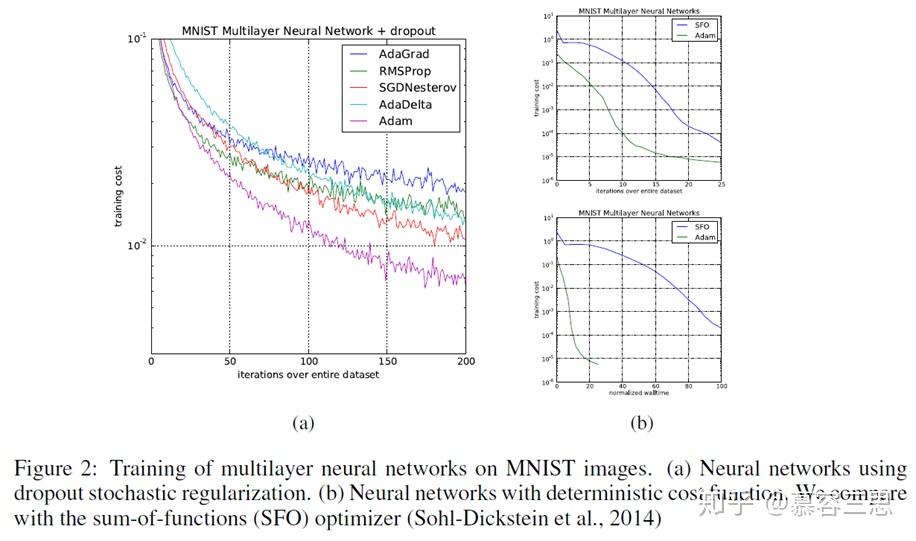
2 MLP验证
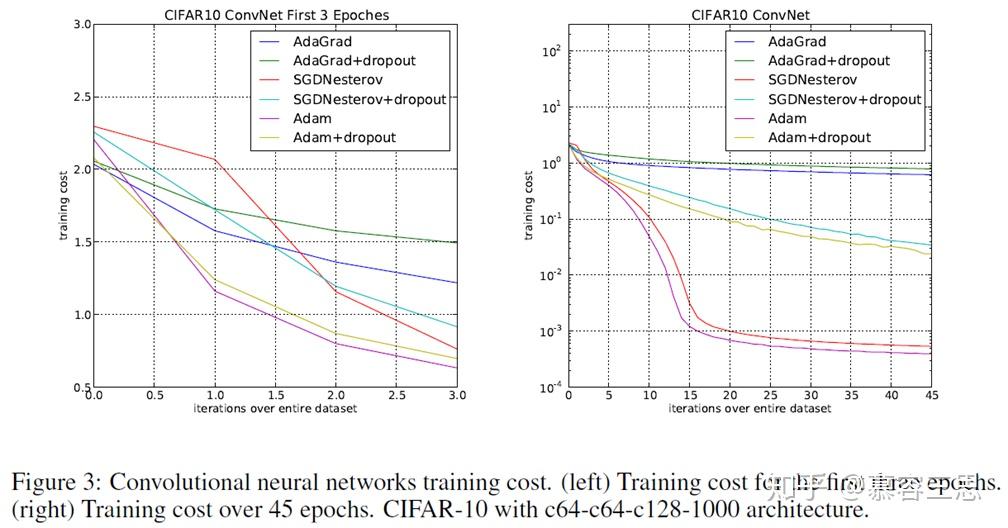
3 CNN验证
4 参数验证
Adam是自适应的矩估计梯度下降算法,在RMSprop的基础上结合了动量的思想,并针对指数加权平均进行了偏差修正。
Adam优点: 1>参数更新的大小不随着梯度大小的缩放而变化;
2>更新参数时的步长的边界受限于超参的步长的设定;
3>不需要固定的目标函数;支持稀疏梯度;它能够自然的执行一种步长的退火。
Adam缺点:1>可能不收敛(ref: On the Convergence of Adam and Beyond, ICLR2018 )
2>可能错过全区最优解 (ref1:The Marginal Value of Adaptive Gradient Methods in Machine Learning, NIPS2017 ; ref2:Improving Generalization Performance by Switching from Adam to SGD))
trick: 1> adam可以结合Nesterov approach进行修正;
2> adam尽管有步长自动退火的功能,但是仍然可以手动设置学习率的递减,并且会有比较好的效果(bert和xlnet训练是均有用到);
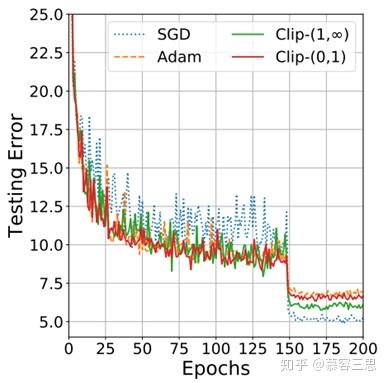
3> 考虑到其收敛性问题,adam可以结合SGD同时使用,即先进行Adam训练,再进行SGD,如下图;

 首页-富联娱乐-富联中国加盟站
首页-富联娱乐-富联中国加盟站
